| Статистика |

Онлайн всего: 3 Гостей: 3 Пользователей: 0 |
|
Конспект по книге С.Куна "Матричные процессоры на СБИС"
[/c]Научно-исследовательский ядерный университет
Московский Инженерно-Физический Институт
Факультет «Автоматики и электроники»
Кафедра «Микро- и наноэлектроники»
Курс «Компьютерный практикум»
Матричные процессоры на СБИС.
Преподаватель: доцент В.А. Лапшинский
Подготовила студент А4-09
Муренко Владимир
Москва 2012 (15.03)
Содержание.
1. Глоссарий
2. Введение
2.1 Общие положения
2.2 Матричные процессоры
2.3 Принцип разработки СБИС архитектур
3. Алгоритмы обработки сигналов и изображений
3.1 Матричные алгоритмы
3.2 Алгоритмы цифровой обработки сигналов
3.3 Матричные алгоритмы на СБИС
4. Отображение алгоритмов на матричные структуры
4.1 Параллельные выражения алгоритма
4.2 Методология обобщенного отображения ГЗ в ГПС
5. Систолические матричные процессоры
5.1 Систолические матричные процессоры
5.2 Отображение ГЗ и ГПС в систолические массивы
5.3 Анализ производительности и оптимизация структуры
6. Волновые матричные процессоры
6.1 Общие представления о волновых процессорах
6.2 Отображение алгоритмов на волновые процессоры
6.3 Языки програмированния для волновых процессоров
7. Заключение
8. Список литературы
1.Глоссарий
Алгоритм - последовательность правил решения некоторой задачи за конечное число шагов.
Систолические процессоры - это новый класс конвейерных матричных структур.
Матрица - образец, модель, штамп, шаблон, форма, инструмент в серийном производстве объектов искусства и техники.
2. Введение
2.1 Общие положения
Возрастающие требования к скорости и производительности реше-ния современных задач обработки сигналов и изображений предопре¬деляют переход к вычислительной супертехнологии. Доступность дешевых высокоплотных высокоскоростных СБИС-приборов и появление САПР предвещают значительный прорыв в области создания и приме¬нения параллельных процессоров. В частности, микроэлектронная технология СБИС должна стимулировать разработку множества новей¬ших проектов архитектур матричных процессоров. Эта тенденция привлекает пристальное внимание правительства, научного и техни¬ческого сообщества. В последнее десятилетие во всем мире наблю¬дается колоссальный рост научно-технических работ, посвященных отображению различных задач обработки сигналов и изображений в такие СБИС-архитектуры.
В данной книге мы подтверждаем необходимость в средствах вы-сокопроизводительных вычислений для научных задач, обработки сигналов и изображений. Современные методы обработки сигналов и изображений в большой степени зависят от развития элементного и архитектурного облика вычислительных средств.[1] Последовательные системы оказываются неадекватными перспективным обрабатывающим системам реального времени и необходимо привлечение дополнитель¬ных вычислительных мощностей в виде параллельных матричных процессоров на СБИС. В большинстве случаев для задач цифровой обработки сигналов (ЦОС) в реальном времени универсальные парал¬лельные компьютеры не могут обеспечить должного уровня произво¬дительности главным образом из-за ощутимых системных накладных расходов. В этой ситуации специализированные матричные процессо¬ры становятся единственной привлекательной альтернативой.
2.2 Матричные процессоры
Вплоть до середины 60-х годов большая часть задач обработки сигналов выполнялась специализированными аналоговыми (в частно¬сти, оптическими) процессорами, поскольку цифровые системы были сложны, потребляли больше энергии и имели невысокую скорость обработки. Однако цифровые системы могут обеспечить лучшую (ино¬гда необходимую) точность, требуемый динамический диапазон, дол¬говременную память и другие преимущества, в том числе програм¬мируемость и расширяемость, позволяющие адаптироваться к измене¬нию требований. В конечном итоге разработчик системы должен вы¬бирать наилучшую из доступных элементную базу, конвейерные мето¬ды и параллельную обработку, обеспечивающие в совокупности дос-тижение требуемой производительности. Реализуемость матричных процессоров на СБИС дает возможность повысить скорость обработки на несколько порядков величины.
При проектировании матричных процессоров на СБИС основное внимание должно быть уделено четырем аспектам: применениям, ал¬горитмам, архитектурам и технологии.
Область применения матричных процессоров на СБИС охватывает обработку изображений, машинное зрение, ядерную физику, струк¬турный анализ, обработку речевых, гидролокационных, радиолокаци¬онных, сейсмических, метеорологических, астрономических, меди¬цинских и других данных. Для успешной разработки матричного про¬цессора требуется понимание процессов формирования сигналов и изображений, класса рассматриваемых алгоритмов и описаний пред¬полагаемых прикладных систем. Например, рассмотрим некоторые технические требования к системе обработки изображений в реаль¬ном времени. Задача состоит в распознавании объекта и проверке его геометрических и физических свойств по некоторым заданным спецификациям для определения, является ли объект целевым или нет.
2.3 Принцип разработки СБИС архитектур
СБИС-архитектуры должны в полной мере использовать возможно¬сти СБИС-технологии, а также принимать во внимание стоимость площади кристалла кремния и входных/выходных выводов. Основное ограничение при компоновке - стоимость межсоединений, зависящая от площади и времени. Значительная стоимость связи обусловлена тем, что провода занимают большую часть пространства схемы и в конечном счете связь снижает тактовую частоту. Когда время за¬держки в схеме начинает зависить главным образом от задержки межсоединений (а не от времени срабатывания логического венти¬ля), минимальные и локальные связи становятся существенным фак¬тором эффективной реализации на СБИС. Другое ограничение СБИС-технологии - сложность схемы, которая может привести к удо-рожанию проекта. Эти проблемы можно решить, используя регуляр¬ные, повторяющиеся архитектурные структуры. Таким образом, в принципах разработки архитектуры на СБИС должны быть заложены модульность, регулярность, локальность связей, массовый парал¬лелизм и минимизированный ввод-вывод.[2] Плодотворной идеей при проектировании является использование стандартных элементов и
эффектов масштабирования. Кроме того, сложность проекта требует разработанных средств автоматизации проектирования, моделирова¬ния и верификации.
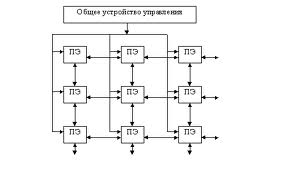
Рис.1 Схема матричного процессора
3. АЛГОРИТМЫ ОБРАБОТКИ СИГНАЛОВ И ИЗОБРАЖЕНИЯ
Алгоритм есть последовательность правил решения некоторой задачи за конечное число шагов. Исследованию различных вычисли¬тельных аспектов алгоритмов обработки сигналов и изображений посвящена обширная литература. Известно также большое число па¬кетов программ, ориентированных на использование при обработке радиолокационных данных, в системах машинного зрения, в ядерной физике, структурном анализе, цифровой обработке сигналов и изо¬бражений в таких приложениях, как анализ речевых и сейсмических сигналов, прогноз погоды, астрономия и медицина
3.1 Матричные алгоритмы
Матричные операции являются основными во многих приложениях, связанных с обработкой сигналов и изображений. Матрица размером mx/i содержит тп элементов (т.е. скаляров), упорядоченных в т строк и п столбцов. Вектор можно рассматривать как частный слу¬чай матрицы. Произвольный /i-мерный вектор, состоящий из п эле¬ментов, может быть представлен как вектор-столбец или вектор-строка.
Треугольное разложение матриц
Известно немало способов треугольного разложения матриц. На-зовем лишь некоторые из них: исключение Гаусса, LU-разложение, QR-разложение. Ниже обсуждается процедура, основанная на QR-разложении. QR-разложение матрицы выполняется с помощью про¬цедуры ортогонализации Грамма - Шмидта или ортогонального преоб¬разования (например, вращение Гивенса (ВГ) или преобразование Хаусхолдера). Поскольку ВГ часто используется в последующих гла¬вах, дадим определение этой операции. Другие методы читатель сможет найти в работе.
QR-разложение на основе ВГ. Произвольную матрицу А можно представить в виде произведения матрицы с ортонормальными стол¬бцами на обратимую верхнетреугольную матрицу: А = QR, где Q - матрица с ортонормальными столбцами, a R - верхнетреугольная матрица. Это разложение, известное как QR-разложение, можно вы¬полнить с помощью последовательности ВГ. ВГ представляет собой численно устойчивый ортогональный оператор, выполняющий двумер¬ное преобразование вращения для обнуления поддиагональных эле¬ментов матрицы А и приведения ее к верхнетреугольному виду. Сна¬чала обнуляются элементы первого столбца, затем - элементы вто¬рого столбца и так до тех пор, пока не будет получена верхне¬треугольная матрица. Рассмотрим эту процедуру более подробно. Для обратимой матрицы А верхнетреугольное разложение получается в результате следующей процедуры:
QTA = R
3.2 Алгоритмы цифровой обработки сигналов
Ниже вводятся такие базовые операции ЦОС, как свертка, корре-ляция, фильтрация, цифровые преобразования.
Дискретные системы и Z-преобразование В задачах ЦОС объектом изучения являются дискретные сигналы и системы. Дискретизованные по времени сигналы возникают либо естественным путем, либо - и это достаточно распространенная ситуация - получаются в результате дискретизации аналоговых (непрерывных по времени) сигналов. В наиболее общей форме опера¬ция над дискретной последовательностью выглядит так: последова¬тельность пропускается через некоторую дискретную систему, и в результате на выходе получаем преобразованную последователь¬ность. Как правило, дискретные системы имеют вполне определенное предназначение и образуют класс линейных инвариантных по времени систем (ЛИВ). Интересно, что ЛИВ-системы полностью характеризу¬ются своим откликом h(n) на единичный импульс 6(л), где последовательность h(n) называют откликом на единичный импульс или импульсной характеристикой системы.
3.3 Матричные алгоритмы на СБИС
Матричные алгоритмы представляют собой набор правил для реше¬ния некоторой задачи за конечное число шагов на большом числе взаимосвязанных процессоров. Поэтому матричный алгоритм зависит как от характеристик вычислительного устройства, так и от стра¬тегий взаимодействия процессоров. Ниже проблеме взаимодействия уделено особое внимание.
Для достижения высокой производительности при вычислениях на СБИС необходимо распараллеливание, которое во многих случаях достигается либо за счет декомпозиции задачи на независимые под¬задачи (выполнимые ’параллельно), либо на зависимые подзадачи, которые выполняются в конвейерном режиме. Степень распараллели¬вания колеблется в зависимости от принятой методики. При отобра¬жении алгоритмов на параллельную систему возникают следующие взаимосвязанные вопросы: как разработка матричного процессора зависит от алгоритма? Какие алгоритмы наилучшим образом отвечают матричной архитектуре?[3] И наиболее важный вопрос: каким образом полностью использовать естественный параллелизм (параллельная и конвейерная обработка) алгоритмов обработки сигналов и изобра¬жений?
Решающее обстоятельство, от которого зависит эффективность матричной обработки, - схема соединения, т.е. схема передачи данных между процессорными элементами (ПЭ) в сети большого раз¬ мера. Соответственно для отображения параллельных алгоритмов на матрицы процессоров необходим их коммуникационный анализ. Для согласования с ограничениями, диктуемыми технологией СБИС, выделим специальный класс алгоритмов, которые назовем рекурсивными, локально зависимыми алгоритмами.
Процедура разработки эффективного алгоритма должна начинаться с ясного понимания спецификаций задачи, ее анализа с математи¬ческой точки зрения и алгоритмического анализа (с точек зрения распараллеливания и вычислительной сложности). Эффективным инс¬трументом анализа и достижения максимального распараллеливания и конвейеризации является граф зависимостей данных, поскольку он полностью выявляет зависимости между данными, которые подверга¬ются обработке алгоритмом. Эти зависимости устанавливают основ¬ные ограничения на процесс обработки. Для эффективного использо-вания потенциального параллелизма матричных процессоров должна быть разработана специальная методология конструирования алго¬ритмов, ориентированная на матричные процессоры.
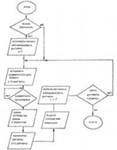
Рис.2 Алгоритм обработки сигнала
4. ОТОБРАЖЕНИЕ АЛГОРИТМОВ НА МАТРИЧНЫЕ СТРУКТУРЫ
4.1 Параллельные выражения алгоритма
Возможны два подхода к образованию параллельных выражений алгоритма:
Векторизация последовательных выражений алгоритма. Непосредственно параллельные выражения алгоритма, такие, как кадры, рекурсивные уравнения, параллельные программы, про-граммы с однократным присваиванием, графы зависимостей и т.д. векторизация последовательных выражений алгоритма Обычно алгоритм записывается в последовательном коде. Языки высокого уровня обеспечивают сжатое выражение алгоритма и явля¬ются машинно-независимым средством программирования. Два из на-иболее употребительных языков Фортран и Алгол, появившиеся в 50-е годы, отражают структуру ранних ЭВМ, призванных выполнять последовательности операций над скалярными данными. Программиро¬вание на этих языках требует разбиения алгоритма на последова¬тельность шагов, каждый из которых выполняет операцию над ска¬лярным объектом. Результирующий порядок вычислений часто ока¬зывается произвольным.
4.2 Методология обобщенного отображения ГЗ в ГПС
Класс однородных (т.е. инвариантных относительно сдвига) ГЗ охватывает широкий диапазон алгоритмов. Многие другие важные алгоритмы, не являясь полностью регулярными, обладают определен¬ий степенью регулярности. И подобная "полурегулярность" может оказаться полезной для эффективного отображения. Поэтому обра¬тимся к методологии обобщенного отображения. Новый подход позво¬ляет применять расширенную классификацию ГЗ и осуществлять выбор между линейными и нелинейными схемами назначения и планирова¬ния. Перспективным является использование множества проекций, допускающих глобальную связь и обработку полностью нерегулярных структур ГЗ. Методология обобщенного отображения позволяет полу¬чить эффективные схемы для многих алгоритмов, в том числе для исключения Гаусса-Жордана, задач поиска кратчайшего пути, тран¬зитивного замыкания, модельного отжига, решения уравнений в частных производных, сингулярного разложения, БПФ и декодирова¬ния Витерби[4].
Назначение узлов и планирование. Для увеличения возможностей выбора среди различных матричных структур введем расширение классов допустимых направлений проекций (назначений узлов) и допустимых планов (назначений планов).
Имеются два основных типа схем назначения узлов.
Линейное назначение (проекция). Линейное назначение ГЗ - это линейное отображение узлов ГЗ в ПЭ, при котором узлы, лежа¬щие на прямой линии, отображаются в один ПЭ. Формально линейное назначение, описываемое матрицей L размером (п - 1) х л, отобра¬жает индекс узла I в вектор S из п - 1 элементов, где S(I) = LI.
Нелинейное назначение. Если назначение узлов не является линейной проекцией, то оно определяется как нелинейное. Планиро¬вание включает определение времени выполнения для всех узлов ГЗ. Спланированное время выполнения узла представляется временным индексом.
5. СИСТОЛИЧЕСКИЕ МАТРИЧНЫЕ ПРОЦЕССОРЫ
5.1 Систолические матричные процессоры
Систолические процессоры - это новый класс конвейерных матричных структур. Систолическая система представ¬ляет собой сеть процессоров, выполняющих ритмичные вычисления и передачу данных по системе. Например, можно показать, что объединение ПЭ, выполняющих элементарную операцию "скалярное произведение" (у«— у + а х Ь) локальными связями, позволит ре¬ализовать цифровую фильтрацию, умножение матриц и другие опера¬ции. Систолический массив обладает важными свойствами модульнос¬ти, регулярности, локального взаимодействия, высоким уровнем конвейерности и синхронизованной мультиобработки. Продвижение Данных в нем обычно описывается с помощью кадров (мгновенных представлений функционирования клеток массива).
Систолический процессор отличается от обычной фоннеймановской машины высоким уровнем конвейерных вычислений, т.е. как только элемент данных поступает из памяти, он может быть эффективно использован в каждой клетке, в которую он попадет при "прокачивании" по всему массиву. Это представляет интерес для широкого класса вычислительных задач, связаных именно с вычисле¬ниями, когда множество операций повторно выполняется над каждым элементом данных. В данном случае устраняются проблемы обмена с памятью, присущие фоннеймановским машинам. Концептуально вычислительные задачи можно разделить на два семейства - вычислительные задачи, связанные с вычислениями, и вычислительные задачи, связанные с ввбдом-выводом. Если в задаче общее число вычислительных операций больше общего числа операций ввода-вывода, говорят, что такая задача связана с вычислениями, в противном случае - с вводом-выводом. Например, обычное умножение матриц является задачей, связанной с вычисле¬ниями, а сложение двух матриц - задачей, связанной с вводом- выводом. Для ускорения решения задач, связанных с вводом- выводом, требуется увеличение доступа к памяти, что при сущест¬вующей технологии крайне затруднительно. В то же время ускорить решение задач, связанных с вычислениями, часто можно за счет использования систолических массивов. Заменяя отдельный процессор одно- или двумерным массивом поцессоров можно достичь увеличения производительности вычислений без увеличения пропуск¬ной способности памяти.
5.2 Отображение ГЗ и ГПС в систолические массивы
Много исследований было посвящено систематическим методам синтеза систолических массивов, основанных на анализе алгорит-мов. Вкратце рассмотрим те работы, которые наиболее близки со-держанию данного раздела. В том же направлении Молдован рассматривал отображение циклических алгоритмов на систолические массивы. Процедура отображения ос¬нована на линейном преобразовании индексных множеств и векторов зависимости данных. Необходимые и достаточные условия существо¬вания справедливых преобразований получены для алгоритмов с кон¬стантными зависимостями данных.[5] При нахождении оптимального про¬екта (для заданной функции стоимости) используется эвристическая процедура для поиска наилучшего преобразования среди множества возможных преобразований. Это отображение может быть распростра¬нено на решение задачи разбиения. Независимо от Молдована аналогичные результаты получены в работе. Pao определил класс алгоритмов, названных регулярными итерационными алгоритмами, которые подобны системам однородных рекуррентных уравнений, рассмотренных Карпом и др. Он показал, что подкласс регулярных итерационных алгоритмов имеет характеристики систолических алгоритмов и для них систематически могут быть получены соответствующие систолические архитектуры. Термин локально рекурсивные алгоритмы, предложенный Куном, указывает на локальность пространственных и временных индексов в рекурсивном (или итерационном) алгоритме, и поэтому такие алгоритмы могут быть представлены в виде пространственно локальных ГЗ или ГПС. В последнее время появилось много резуль¬тативных исследований в этом направлении.
5.3 Анализ производительности и оптимизация структуры
Этот раздел посвящен производительности и оптимальности си-столических массивов. Очень трудно определить наиболее подходя¬щий критерий оптимальности, а оптимизация одного фактора может оказать влияние на другие факторы. И тем не менее существуют несколько полезных формул и наблюдений, которые помогают в поис¬ке оптимальной структуры.
Существует множество факторов, определяющих критерий опти-мальности при разработке систолических массивов. Окончательный выбор критериев оптимальности зависит от области применения. К числу наиболее типичных факторов следует отнести: время вычис¬лений, конвейерный такт, блочный конвейерный такт, размер масси¬ва, каналы ввода-вывода. Уточним их определения.
Время вычислений Т: интервал времени между началом первого вычисления и окончанием последнего вычисления для одной решаемой на процессорном массиве задачи.
Конвейерный такт а: интервал времени между двумя последова-тельными вычислениями в процессоре.
Блочный конвейерный такт /3: интервал времени между началом двух последовательных задач, выполняемых в процессорном массиве.
Размер массива: число процессоров в массиве. Размер массива, очевидно, определяет базовую стоимость аппаратуры.
Каналы ввода-вывода: число каналов ввода-вывода, связывающих с внешним миром (основной машиной). Число каналов ввода-вывода непосредственно влияет на стоимость аппаратуры.
Иногда представляет интерес комбинация двух или нескольких из перечисленных факторов. Например, произведение размера массива на время вычислений является полезной мерой для оценки аппарату¬ры по критерию "стоимость-эффективность". Другой полезный кри¬терий - использование процессора, которое зависит от конвейерно¬го такта, блочного конвейерного такта и схем ввода данных. Ниже приводятся возможные варианты, из которых видно, как в различных приложениях естественно возникают определяющие критерии проекти¬рования.
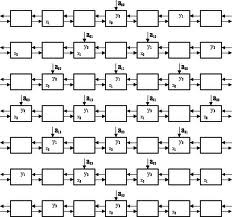
Рис.3 Вычислительные системы с систалической структурой
6. ВОЛНОВЫЕ МАТРИЧНЫЕ ПРОЦЕССОРЫ
6.1 Общие представления о волновых процессорах
Структуры матричных процессоров можно разбить на две основные группы: синхронные и асинхронные. При увеличении размеров матриц и тактовой частоты синхронные структуры, основанные на глобаль¬ной синхронизации, становятся менее эффективными, что приводит к необходимости использовать другие возможные схемы синхронизации. ]. В кольцевом матричном процессоре использовано последовательное соединение узловых процессоров, т.е. выход процессора соединяется с вхо¬дом процессора и т.д., а выход процессора п соединен со вхо¬дом первого узлового процессора. В обычной конфигурации один узловой процессор используется для операций ввода-вывода, а центральный тактовый генератор - для синхронной передачи данных по кольцу (например, кольцевой систо-лический процессор). Как уже говорилось выше, в больших (длин-ных) матричных процессорах расфазировка синхронизирующих импуль¬сов может быть значительной. Каждый процессорный эле-мент (ПЭ) использует синхроимпульсы, поступающие от левого ПЭ, и генерирует новый синхроимпульс для передачи правому ПЭ. Таким образом, передача данных ресинхронизирована с помощью синхроим¬пульсов в каждом ПЭ. К сожалению, такую схему нельзя использо¬вать в более сложных структурах матричных процессоров, таких, как двумерный матричный процессор.
6.2 Отображение алгоритмов на волновые процессоры
Существуют три подхода при формировании волновых процессоров: Трассировка вычислительных волновых фронтов и их "прокач¬ка" через матрицу процессоров. Отображение ГЗ непосредственно на волновой процессор (или ГПД). Преобразование матричного процессора, описанного ГПС, в волновой процессор (ГПД) с помощью соответствующего представле¬ния нескольких ключевых элементов аппаратуры с управлением пото¬ком данных. Понятие вычислительных волновых фронтов Понятие вычислительных волновых фронтов предлагает очень простой способ разработки вычисления волнового фронта, который состоит из трех шагов: Разбить алгоритм на упорядоченную последовательность ре¬курсий. Отобразить рекурсии на соответствующие вычислительные вол-новые фронты в процессоре. Последовательно "прокачать" волновые фронты через матрицу процессоров.
6.3 Языки программирования для волновых процессоров
Существуют два фундаментальных понятия в волновой обработке - параллелизм и связь. Понятия параллельных процессов и понятия канала были введены в работе Ч.Хоара как параллельные команды и команды ввода-вывода. Изучение модулей и процессов проводилось также в работах. Формальную мо¬дель модулей и процессов представляют абстрактные машины, математические основы которых даны в работе. Алгебраическая спецификация призвана выразить модули в терминах параметризованных абстрактных типов данных. Параллелизм и конвейеризация. Параллелизм обычно достигается разбиением задачи на независимые подзадачи или на конвейеризо¬ванные подзадачи.
Обычные языки программирования для мультипроцессорных систем описывают только глобальный параллелизм при обработке данных. Они не могут описывать параллельные пересылки данных, которые встречаются в среде конвейерной обработки. Системы на СБИС со¬держат огромное число ПЭ, и прямая пересылка данных между ПЭ увеличивает скорость и облегчает проблему хранения данных путем сокращения числа операций считывания из памяти и записи в па¬мять. Критическим в языках для СБИС является способ выражения свойств конвейеризации и потока данных. Поэтому предпочтительнее использовать итеративные или рекурсивные представления и функци¬ональные выражения.

Рис.4 Волновой матричный процессор
7.Заключение
Книга начинается с анализа алгоритмов для представляющих интерес приложений и за¬канчивается разработкой систолических СБИС-вычислителей. В зада¬чах обработки сигналов и изображений используются обычно алго¬ритмы, детерминированные в пространстве и во времени, что позво¬ляет решать задачи оптимизации алгоритмов и архитектур в рамках единой методологии. Специализированные параллельные системы ста-новятся преобладающим и многообещающим направлением разработки суперкомпьютеров будущих поколений. В ближайшее время мы станем свидетелями роста числа специализированных систолических процес¬соров и специализированных ЭВМ, предназначенных для выполнения базовых алгоритмов обработки сигналов и изображений, линейной алгебры и научных расчетов, и, следовательно, рассмотренные в этой книге задачи анализа параллельных алгоритмов, методология их разработки и отображения на СБИС найдут широкое применение.
Уже в ближайшем будущем мы столкнемся с вызовом современных и "интеллектуальных", т.е. обладающих способностью к восприятию, суперкомпьютерных систем, которые станут лучше адаптироваться к среде функционирования и будут более естественным и эффективным образом взаимодействовать с пользователем с помощью интеграции логических цепей и сенсорных стимуляторов. Реализация новейших концепций в области вычислений позволит также обратиться к реше¬нию ранее неразрешимых задач. С точки зрения таких систем пред¬ложенные в этой книге системы с массовым параллелизмом можно рассматривать всего лишь в качестве базовых примитивов, которые лягут в основу новейших вычисляющих (или думающих) машин.
В заключение отметим, что грядущие технологии СБИС обещают рост вычислительной производительности. Совокупная производи-тельность описывается не только в терминах площади кремниевого кристалла, быстродействия или вычислительной мощности устрой-ства, но и характеризуется развитием новейших систем, находящих¬
8.Список Литературы
1. D. H. Ackley, G. E. Hinton, and T. J. Sejnowski. A learning algorithm for Boltzmann machines, 1985.
2. H.C. Andrew and C.L. Patterson. Singular value decompo¬sitions and digital image processing. IEEE Transactions on ASSP, pp. 26-53, Feburary 1976.
3. W. D. Ashcraft and H. M. South. Architecture and control of a distributed signal processor. In Proc. IEEE ICASSP’8J[, San Diego, Calif., pp. 44.8.1 - 44.8.4, 1984.
4. К91 Матричные процессоры на СБИС С. Кун, 1991г.
5. K. Hwang and Joydeep Ghosh. Supercomputer and Artificial Intelligence Machines. Technical Report CRI-87-03, Univer¬sity of Southern California, January 1987.
[c][l] |
| Категория: Конспекты (курсы КП и ПК) | Добавил: Murenko (26.06.2012)
|
| Просмотров: 3665
| Рейтинг: 0.0/0 |
Добавлять комментарии могут только зарегистрированные пользователи. [ Регистрация | Вход ] |
|
