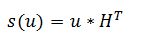НАУЧНО-ИССЛЕДОВАТЕЛЬСКИЙ ЯДЕРНЫЙ УНИВЕРСИТЕТ МОСКОВСКИЙ ИНЖЕНЕРНО-ФИЗИЧЕСКИЙ ИНСТИТУТ
Курс «Компьютерный практикум»
Конспект по книге: «Коды и математика»
Преподаватель: доцент В.А. Лапшинский Подготовил: студент А4-09 Клоков Н.М.
Москва 2014
Аннотация
В популярной форме книга знакомит читателя с основными понятиями и идеями теории эффективного и помехоустойчивого кодирования.
Имея своими первоисточниками криптографию (искусство засекречивания истинного содержания сообщения), но главным образом решая различные проблемы, возникающие при передаче информации по линиям связи, теория кодирования в настоящее время выросла в обширную и разветвленную область знания со своим кругом объектов и задач.
Глоссарий
Сумматор ‒ устройство, преобразующее информационные сигналы (аналоговые или цифровые) в сигнал, эквивалентный сумме этих сигналов. Триггер ‒ класс электронных устройств, обладающих способностью длительно находиться в одном из двух устойчивых состояний и чередовать их под воздействием внешних сигналов. Код ‒ правило (алгоритм) сопоставления каждому конкретному сообщению строго определённой комбинации символов (знаков) (или сигналов)
Оглавление
1. Введение 2. Основной текст 2.1 Знакомство с кодированием 2.2 Углубленное изучение кодирования 3. Заключение 4. Список литературы
ВВЕДЕНИЕ
В данной книге подробно рассказывается о кодировании. История, шифры, оптимальные коды и шумы, многое рассмотрено в данном издании. Достаточно небольших знаний об окружающем нас мире, чтобы понимать, что кодирование используется в очень важном для настоящего времени явлении. Конечно, это Интернет. В книге также упомянут этот пункт и подробно исследовано, как и где его применяют. Первая часть книги написана вполне элемен¬тарно, и для ее понимания читателю достаточно знать простейшие законы математики.
В дальнейшем изложении, однако, существенно используются основные факты линейной алгебры, а также факты, связанные с понятиями поля и группы.
Книга разбита на главы. Каждая глава содержит какой-либо элемент истории или теории кодирования.
ЗНАКОМСТВО С КОДИРОВАНИЕМ
Первая глава содержит описание истории кодирования. Коды появились в глубокой древности в виде криптограмм (по-гречески - тайнописи), когда ими пользовались для засекречивания важного сообщения от тех, кому оно не было предназначено. Уже знаменитый греческий историк Геродот (V век до н. э.) приводил примеры писем, понятных лишь для одного адресата. В средние века и эпоху Возрождения над изобретением тайных шифров трудились многие выдающиеся люди, в их числе философ Фрэнсис Бэкон, крупные математики Франсуа Виет, Джероламо Кардано, Джон Валлис. Читатель также может ознакомиться с простейшей из кодировок. Двоичная кодировка представлена в таблице 1.
Сказанное здесь - это лишь первые подступы к проблеме кодирования, которой посвящена эта книга. Пока же отметим только, что наряду с двоичными кодами применяют коды, использующие не два, а большее число элементарных сигналов, или, как их еще называют, кодовых символов.
Во второй главе речь идет о шифрах. Приемов тайнописи - великое множество, и, скорее всего, это та область, где уже нет нужды придумывать что-нибудь существенно новое. Наиболее простой тип криптограмм - это так называемые подстановочные криптограммы. Составляя их, каждой букве алфавита сопоставляют определенный символ (иногда тоже букву) и при кодировании всякую букву текста заменяют на соответствующий ей символ. Буквы текста, который должен быть передан в зашифрованном виде, первоначально записываются в клетки прямоугольной таблицы, по ее строчкам. Буквы ключевого слова пишутся над столбцами и указывают порядок (нумерацию) этих столбцов способом, объясняемым ниже. Чтобы получить закодированный текст, надо выписывать буквы по столбцам с учетом их нумерации.
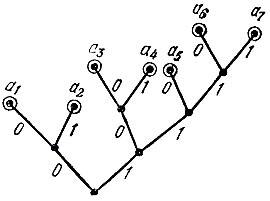
Третья глава рассказывает о коде Фано. Алгоритм кодирования Фано имеет очень простую графическую иллюстрацию в виде множества точек (вершин) на плоскости, соединенных отрезками (ребрами) по определенному правилу (такие фигуры в математике называют графами). Граф для кода Фано строится следующим образом. Из нижней (корневой) вершины графа исходят два ребра, одно из которых помечено символом 0, другое -символом 1. Эти два ребра соответствуют разбиению множества сообщений на две равновероятные группы, одной из которых сопоставляется символ 0, а другой - символ 1. Ребра, исходящие из вершин следующего "этажа", соответствуют разбиению получившихся групп снова на равновероятные подгруппы и т. д. Построение графа заканчивается, когда множество сообщений будет разбито на одноэлементные подмножества. Каждая концевая вершина графа, т. е. вершина, из которой уже не исходят ребра, соответствует некоторому кодовому слову. Пример изображен на рисунке 1.
Рис.1 Пример графа
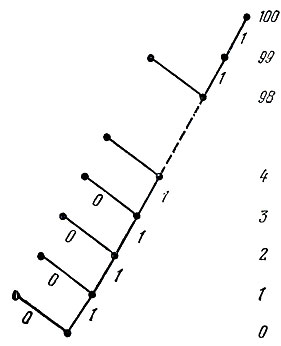
Четвертая и пятая глава содержит информацию о свойствах префикса. Наиболее простыми и употребляемыми кодами без запятой являются так называемые префиксные коды, обладающие тем свойством, что никакое кодовое слово не является началом (префиксом) другого кодового слова. Если код префиксный, то, читая кодовую запись подряд от начала, мы всегда сможем разобраться, где кончается одно кодовое слово и начинается следующее. Кодовое дерево для требуемого кода, содержащее 100 "этажей", изображено на рис. 2 (пунктиром отмечены пропущенные этажи).
Рис.2 Пример кодового дерева
В главах с шестой по девятую идет повествование об оптимальном коде, шумах и избыточности, антиподах и коде Хемминга. Как уже говорилось, общее правило при построении экономного кода следующее: чаще встречающиеся сообщения нужно кодировать более короткими кодовыми словами, а более длинные слова использовать для кодирования редких сообщений. Это правило и было реализовано в рассмотренном выше методе кодирования Фано. Но всегда ли метод Фано приводит к наиболее экономному коду? Напомним читателю, что при кодировании сообщений нужно заботиться о том, чтобы их передача была достаточно быстрой, удобной и надежной. До сих пор мы интересовались лишь требованием быстроты. В этой связи были рассмотрены различные эффективные методы кодирования: коды Фано, Шеннона, Хаффмена. Последний, как было выяснено, является даже оптимальным при заданном множестве сообщений с заданными вероятностями. Указанные методы можно рассматривать как своего рода искусственные языки, предназначенные для экономной передачи информации. Оказывается, что привычные нам естественные языки (русский, английский и т. д.) являются в этом плане слишком расточительными и не выдерживают конкуренции с искусственными языками. Мы выяснили, что при построении помехоустойчивых кодов не обойтись без дополнительных символов, которые должны быть присоединены к кодовым словам безызбыточного кода. Эти символы уже не несут информации о передаваемом сообщении. Пусть количество сообщений, которые требуется передавать абоненту, равно 16. Для их безызбыточного кодирования можно использовать двоичные слова длины 4, но тогда код не будет корректировать ошибки. При использовании слов длины 5, как мы уже знаем, можно обнаружить, но не исправить любую одиночную ошибку.
УГЛУБЛЕННОЕ ИЗУЧЕНИЕ КОДИРОВАНИЯ
Во второй части автор углубляется в архитектуру кодов, рассматривает всевозможные варианты и способы кодирования с точки зрения степени защиты информации и оптимальности кода.
В главах 10 — 14 рассказывается о линейных и групповых кодах, а также циклических кодах и кодах, исправляющих несимметричные ошибки. Большинство рассмотренных выше кодов обладало следующим свойством: сумма (и разность) двух кодовых слов также являлась кодовым словом. Для кода с повторением это свойство очевидно. Ясно оно и для кода с общей проверкой на четность, потому что сумма двух слов с четным числом единиц есть также слово с четным числом единиц. Слово "синдром" означает обычно совокупность признаков, характерных для того или иного явления. Такой же примерно смысл имеет понятие "синдром" и в теории кодирования. Синдром вектора, содержащего, быть может, ошибки, дает возможность распознать наиболее вероятный характер этих ошибок. Правда, определение, которое мы приводим ниже, не сразу позволяет это увидеть. Синдромом вектора и называется вектор s(u), определяемый равенством:
На практике нередко встречаются каналы, отличающиеся асимметричным характером ошибок, скажем, такие, в которых преобладают замещения вида 0 → 1 (т. е. вместо нуля принимается единица), а замещения 1 → 0 крайне редки. Конечно, и в этом случае можно использовать коды, предназначенные для исправления замещений обоих видов, в частности, рассмотренный нами код Хемминга. Но это было бы слишком расточительно, так как корректирующая способность кода наполовину расходовалась бы тогда вхолостую. Придуманы поэтому коды, приспособленные специально к исправлению несимметричных ошибок. Среди линейных кодов особо важную роль играют так называемые циклические коды. По ряду причин они являются наиболее ценным достоянием теории кодирования. Во-первых, они допускают еще более компактное описание, чем произвольные линейные коды. Во-вторых, имеющиеся для линейных кодов алгоритмы кодирования и декодирования могут быть в применении к циклическим кодам значительно упрощены; более того, для циклических кодов существуют свои особые методы декодирования, неприложимые к другим линейным кодам. Наконец, по своей структуре эти коды идеально приспособлены к реализации в современных технических устройствах.
Главы 15 — 18 содержат описание использования кодов в повседневной жизни, а также в окружающем нас мире. Одна из основных проблем теории кодирования (и, пожалуй, самая интригующая) формулируется следующим образом: “Каково максимальное число кодовых слов в двоичном коде длины n, если наименьшее расстояние между кодовыми словами равно d?”. Ответ на поставленный вопрос позволил бы во всех случаях выяснить, какой наименьшей длины должен быть код, чтобы можно было, во-первых, передать нужное число сообщений, и во-вторых, гарантировать исправление (или обнаружение) данного числа ошибок. Однако здесь мы сталкиваемся с явлением весьма распространенным в математике, когда простая по формулировке задача оказывается далеко не столь простой для решения. Более реальный, хотя тоже нелегкий путь, по которому и идут исследования, заключается в том, чтобы достаточно точно оценить это число. Вряд ли было бы целесообразно привлекать универсальные ЭВМ для кодирования и декодирования с помощью линейных и циклических кодов. Однако устройства или схемы, предназначенные для этих целей, состоят из тех же элементов, что и любая ЭВМ, так что такие схемы, если угодно, можно рассматривать как специализированные мини-ЭВМ. В случае двоичных кодов применяются элементы двух основных типов:
Хотя в процедуре принятия решения большинством голосов нет для нас ничего необычного, может все же показаться неожиданным, что метод голосования используется при декодировании помехоустойчивых кодов.
Главы 19 — 21 иллюстрируют некоторые особенности кодов на различных примерах.
ЗАКЛЮЧЕНИЕ
Мы познакомились, конечно, далеко не со всеми задачами этой теории, но в той или иной мере затронули три ее основных направления - кодирование с целью засекречивания сообщений, кодирование с целью сжатия информации, наконец, кодирование с целью исправления и обнаружения ошибок. Хотелось бы дать представление читателю, сколь широки и многообразны связи этой теории с разными разделами математики, и как порой самые абстрактные математические теории могут с успехом применяться для решения практических задач. Дальнейшее проникновение в проблематику теории кодирования (подробное изучение циклических кодов и их обобщений, знакомство с кодами, исправляющими пакеты ошибок, и специфическими алгоритмами их декодирования и т. д.) требует уже значительно более серьезной математической подготовки.
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ
1. Аршинов М.Н., Садовский Л.Е. “Коды и математика” (рассказы о кодировании) 2. URL – http://mathemlib.ru/books/item/f00/s00/z0000023/index.shtml 3. URL – http://booksshare.net/books/math/arshirov-mh/1983/files/