| Статистика |

Онлайн всего: 1 Гостей: 1 Пользователей: 0 |
|
Человеческий мозг как узел сети и его вычислительная модель.
ОГЛАВЛЕНИЕ
Введение. Зачем все это? 2
2. Вычислительная модель Б. Хайеса 2
2.1 Модель памяти. 3
2.2 Критический радиус. 6
2.3 Реализация SDM. 8
2.4 Ассоциативные связи. 9
2.5 Заключение 10
3. Сеть Хопфилда. 10
3.1 Структура. 11
3.2 Обучение. 12
4. Мозг как узел сети. 12
Заключение. 12
Список литературы 13
ВВЕДЕНИЕ. ЗАЧЕМ ВСЕ ЭТО?
Использование программ, структурно повторяющих, похожих на устройство человеческой нервной системы сегодня распространено во всех сферах – от расчетов NASA до агентств по продаже недвижимости. Экономисты говорят о четвертой промышленной революции, характеризующейся внедрением ИИ в сферы производства и услуг, поэтому процессы моделирования интеллекта сейчас интересуют людей за пределами университетских кабинетов.
2. ВЫЧИСЛИТЕЛЬНАЯ МОДЕЛЬ Б. ХАЙЕСА
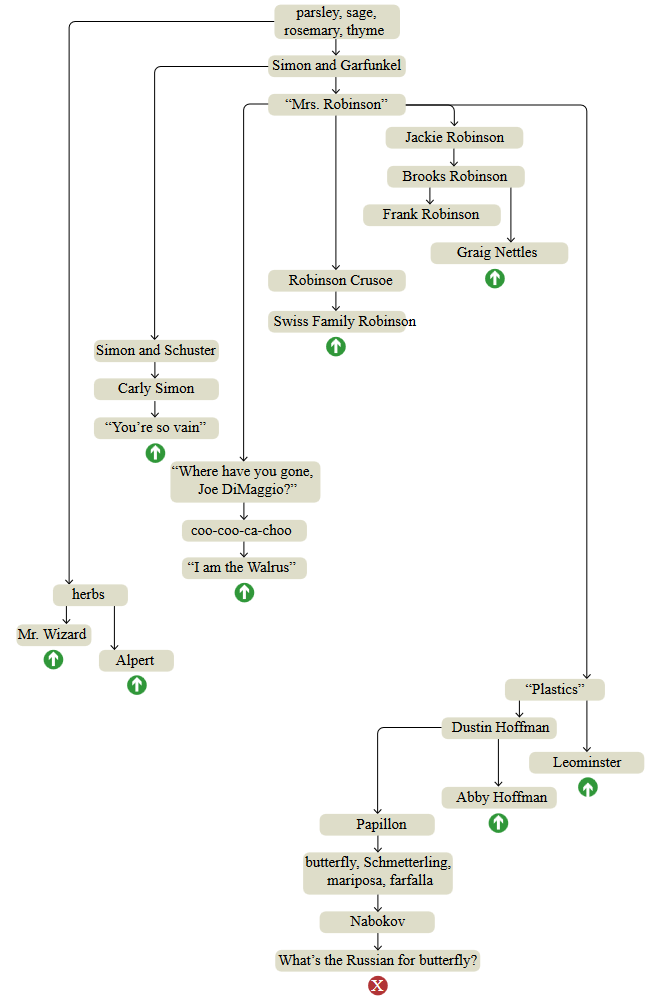
Бриан Хайес в своей статье «The Mind Wanders» описывает попытку сконструировать модель человеческой памяти, имитируя явление, которое в быту носит название поток мыслей. Сначала он провел эксперимент со свободными ассоциациями, начав с растительной тематики. Схема ниже представляет собой реконструкцию хода размышлений, ту последовательность, с которой темы всплывали в уме. (рис. 1) [1]
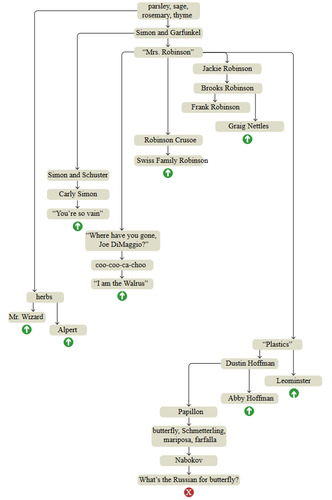
Рис. 1 Запись мысленного эксперимента.
Как можно заметить, схема не является линейной, а представляет собой дерево с короткими цепочками последовательных ассоциаций, оканчивающихся резким возвратом к более раннему узлу (такие прерывания обозначены зеленой стрелочкой, красным крестиком обозначено окончание эксперимента).
2.1 МОДЕЛЬ ПАМЯТИ.
Как можно реализовать алгоритм, описывающий случайное блуждание по ассоциациям? Важно помнить, что такое блуждание вовсе не является случайным: ассоциации в человеческой голове не равновероятны, и зависят от недавней умственной активности человека – для этого в модели необходим механизм динамической регуляции вероятностей целых категорий узлов в зависимости от того, какие узлы были посещены недавно.
Так же в модели должен быть механизм, возвращающий алгоритм на один из предыдущих узлов, следовательно, в каждый недавно посещённый узел необходимо добавить в список вариантов целей, даже если он никак не связан с текущим узлом. Но привыкание — тоже вероятность: слишком часто вспоминаемые мысли становятся скучными, поэтому должны подавляться в модели.
В заключение, модель должна учитывать, что у некоторых воспоминаний есть нарративная структура с событиями, разворачивающимися в хронологическом порядке. Для узлов таких эпизодических воспоминаний требуется ребро next, а возможно и previous.
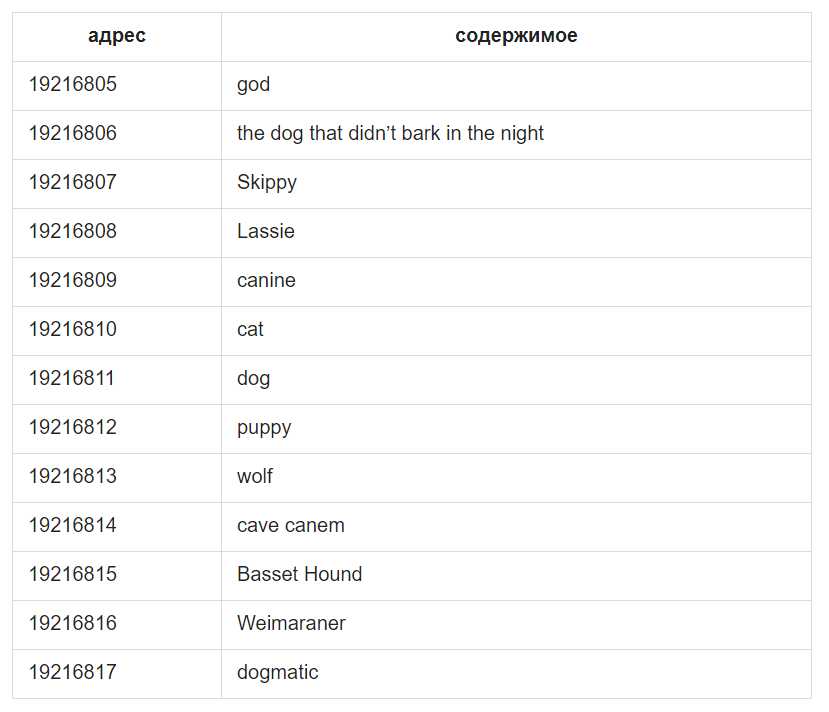
В структуре данных для реализации данной модели, с точки зрения банков памяти цифрового компьютера, схожие вещи будут храниться по соседним адресам. Вот гипотетический сегмент памяти, центрированный на концепции dog. Соседние места заняты другими словами, понятиями и категориями, которые скорее всего будут вызваны мыслью о собаке (dog): очевидные cat (кошка) и puppy (щенок), различные породы собак и несколько конкретных собак, а также, возможно, более сложные ассоциации. У каждого элемента есть цифровой адрес. Адрес не имеет какого-то глубинного значения, но важно то, что все ячейки памяти пронумерованы по порядку.[2]
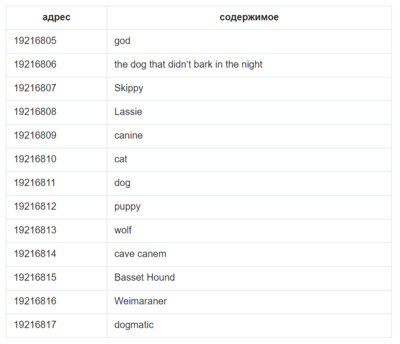
Рис. 2 Одномерная модель хранения элементов.
Но окружив dog всеми его непосредственными ассоциациями, не остается места для их ассоциаций. Собачьи термины хороши в своём собственном контексте, но для контекста cat (kitten, tiger, nine lives) не остается места. В одномерном массиве нет никакой возможности встроить каждый элемент памяти в подходящее окружение.
Давайте перейдем в два измерения. Разделив адреса на два компонента, мы задаём две ортогональные оси. Первая половина каждого адреса становится координатой x, а вторая — координатой y. Теперь dog и cat по-прежнему остаются близкими соседями, но также у них появляются личные пространства, куда могут быть помещены ассоциации. (рис. 3)
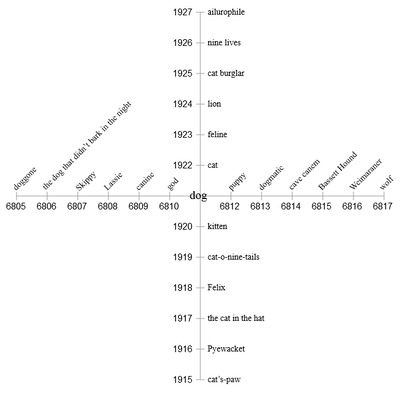
Рис. 3 Двумерная модель памяти.
Однако двух измерений тоже недостаточно. Элементы неизбежно начнут сталкиваться и конфликтовать с близкими элементами.
Здесь приходит на помощь идея разреженной распределённой памяти (sparse distributed memory), которую придумал Пентти Канерва в конце 1980-х. Есть куб в 3-ч измерениях (рис. 4). Если принять, что длина стороны равна единице измерения, то восемь векторов можно обозначить векторами из трёх двоичных цифр, начиная с 000 и заканчивая 111 . В любой из вершин изменение единственного бита вектора приводит нас к вершине, являющейся ближайшим соседом. Изменение двух битов перемещает нас к следующему по близости соседу, а замена всех трёх битов приводит к противоположному углу куба — к самой отдалённой вершине.
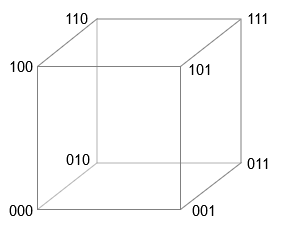
Рис. 4 Трехмерная модель памяти.
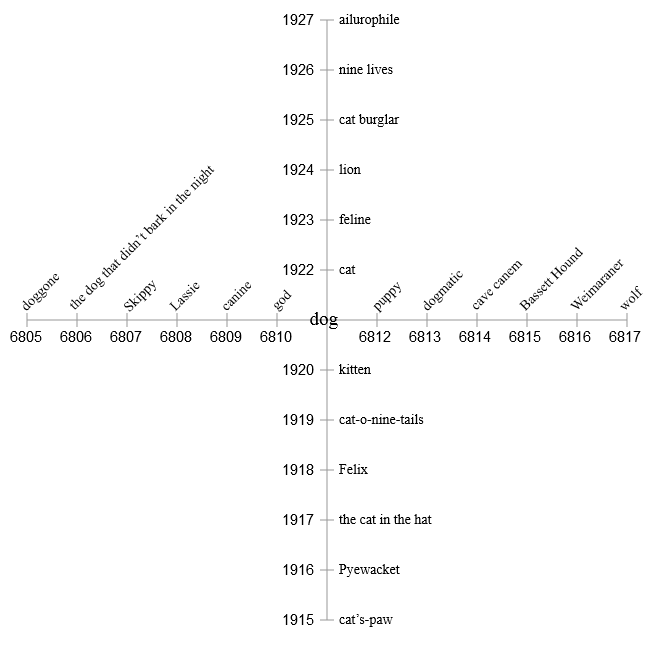
Для четырехмерного куба похожая история – 16 вершин, векторы содержат все сочетания двоичных цифр от 0000 до 1111, и далее, обобщая 1000 цифр. Если мы используем манхэттанскую метрику – перемещаемся всегда по ребрам и никогда по диагонали – то расстояние между двумя любыми векторами определяется количеством позиций, на которые отличаются эти два вектора (число Хэмминга), которое можно найти, выполнив над векторами исключающее или.
2.2 КРИТИЧЕСКИЙ РАДИУС.
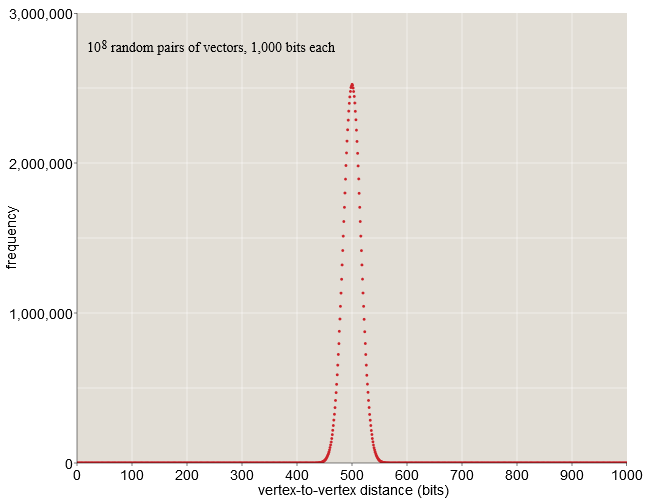
В 1000 мерном кубе с 21000 вершин наблюдаются интересный эффект. Для его наблюдения выберем две случайные вершины и попытаемся вычислить ожидаемое расстояние. Это задача подсчета позиций, в которых различаются два вектора. Для случайных векторов каждый бит может быть с равной вероятностью быть равным 0 или 1, поэтому ожидается, что векторы будут различаться в половине битовых позиций. В случае 1000-битного вектора стандартное расстояние равно 500 битам. Более того, все расстояния между векторами тесно скапливаются вокруг среднего значения в 500. В выборке из ста миллионов случайных пар ни одна из них не ближе, чем 400 бит или дальше, чем 600 бит (рис. 5).
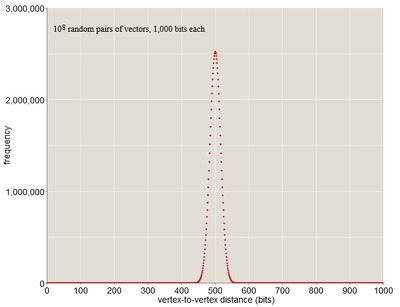
Рис. 5 Зависимость частоты появления паттерна от битового радиуса.
Атомов во вселенной не хватит, чтобы построить структуру из 21000, и не нужно. Нам необходимо пространство только для тех элементов, которые мы хотим хранить. Можно сконструировать 108 элементов – Канерва называет их твердыми ячейками, а остальное оставить недостроенным. Построенное множество будет демонстрировать то же сжатое распределение расстояний, что и полный куб – это следует из графика. Преимущество этой архитектуры – элемент может распределиться по обширной области, не мешая своим соседям.
В отличие от традиционной памяти, SDM имеет огромное адресное пространство – 21000 – но только малая, случайная его часть существует физически – поэтому она разряженная, и отдельный элемент не храниться в одном месте, а распределен по области – распределенная. Кроме того, в каждой ячейке может храниться несколько элементов данных, следовательно, размывается различие между адресом и содержимым памяти. Память также отзывается не на точное совпадение, а на наилучшее совпадение.
При поступлении вектор Х (его значение также является и адресом) сохраняется во все твердые ячейки, находящие в пределах определённого расстояния (451 бит) от Х. Значение вектора Y не будут не перезаписывать, а дополнять значения в ячейках.
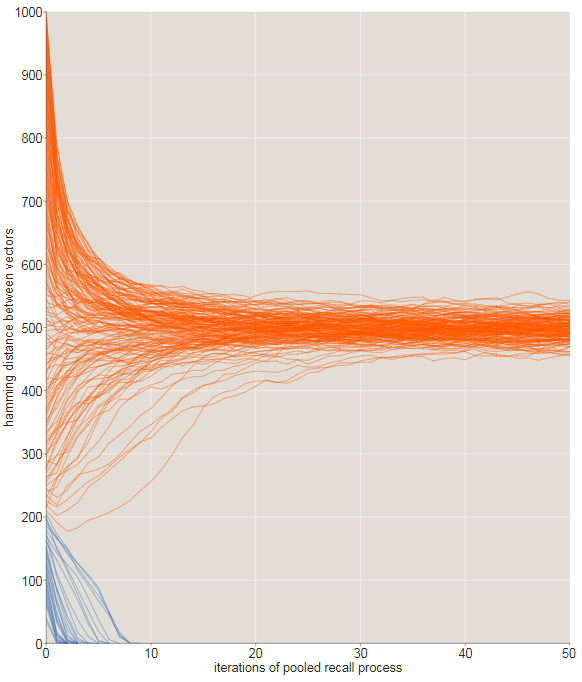
SDM может делать то, на что неспособна традиционная память - извлекать информацию на основе частичных или приблизительных данных. Если неправильный вектор не отличается от записанного на критическое расстояние, то его можно достать из памяти – передать в функцию поиска, она найдет наиболее подходящее значение, это значение вновь передать в функцию поиска и т.д. Критический радиус равен приблизительно 209 битам, или не более 20% вектора может быть повреждено. (рис. 6) [1]
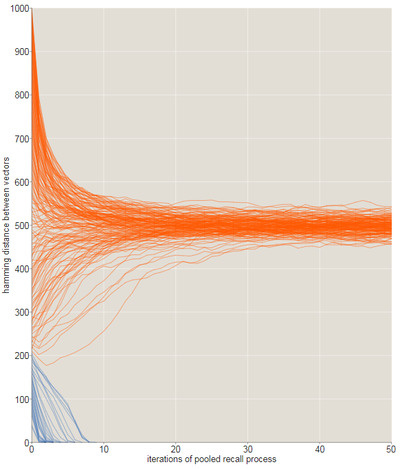
Рис. 6 Эволюция последовательностей рекурсивных воспоминаний с помощью исходных сигналов, отличающихся от целевого.
Основное преимущество распределенной памяти – устойчивость к аппаратным сбоям и ошибкам. Когда у каждого хранящегося паттерна есть тысяча копий, ни одно место не является принципиальным. Можно стереть всю информацию, хранящуюся в 60 %твёрдых ячеек, и всё равно иметь идеальное вспоминание , если считать, что мы передаём в качестве сигнала абсолютно точный адрес. При частичных сигналах критический радиус сжимается при увеличении потерянных мест. После уничтожения 60% мест критический радиус сжимается с 200 бит до примерно 150 бит. После уничтожения 80 % мест память оказывается серьёзно повреждена, но не уничтожена.
2.3 РЕАЛИЗАЦИЯ SDM.
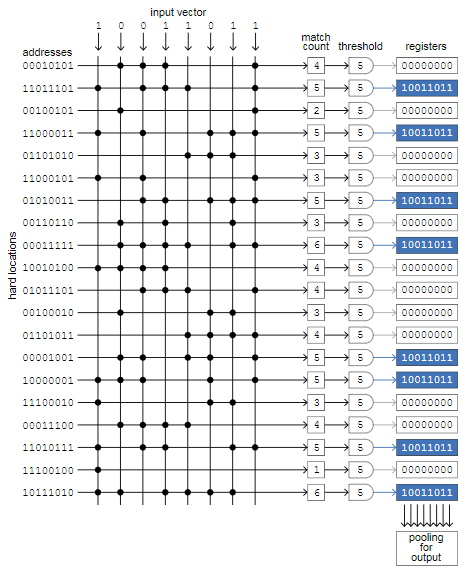
Способ реализации SDM – перекрестная матрица, строки соответствуют твердым ячейкам памяти, столбцы – сигналы, имитирующие отдельные биты входного вектора. В каноничной памяти миллион строк, и каждой из них назначен 1000-битный адрес, и 1000 столбцов. Принцип работы демонстрируется на 20 строках и 8 столбцов (рис. 7).
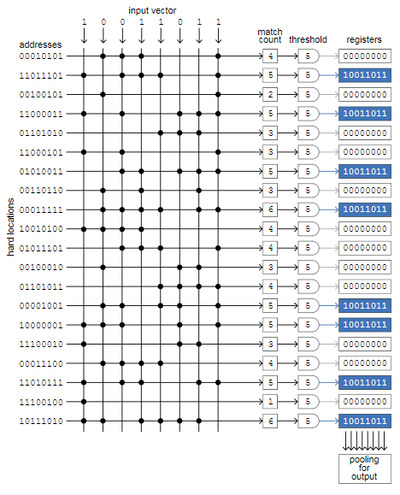
Рис. 7 Способ реализации SDM через перекрестную матрицу.
Проиллюстрированный на схеме процесс заключается в сохранении одного входного вектора в пустую память. Восемь входных битов одновременно сравниваются со всеми 20 адресами твёрдых ячеек. Когда входной бит и бит адреса совпадают — ноль с нулём или единица с единицей — мы ставим на пересечении столбца и строки точку. Затем мы считаем количество точек в каждой строке, и если количество равно или превышает пороговое значение, то мы записываем входной вектор в регистр, связанный с этой строкой (синие поля). В нашем примере пороговое значение равно 5, и в 8 из 20 адресов есть не менее 5 совпадений. В 1000-битной памяти пороговое значение будет равно , а 451 выбраны окажутся всего около одной тысячной всех регистров.
В канонической модели сравнения битов происходит одновременно, поэтому время доступа для чтения(записи) не зависит от количества твердых ячеек. Это называется ассоциативной памятью, или адресацией по содержимому, используется в вычислительных областях, например, в Большом адронном коллайдере или передаче пакетов через маршрутизатор. Структуру можно увязать со структурой мозга: строки – плоские, веерообразные клетки Пуркинье, столбцы – параллельные волокна, протянувшиеся по всем клеткам Пуркинье.
Однако в традиционном процессоре нет способов одновременного сравнения всех входных битов нет. Придется обходить миллион ячеек, и в каждом месте сравнивать тысячи пар битов. Можно при записи вектора сохранять указатель на каждую ячейку из радиуса. В итоге при ссылке на этот элемента нужно будет обходить только 1000 сохраненных указателей. Минусы – если при приблизительных запросах ни одна из ячеек не будет найдена, то придется сканировать все ячейки.
2.4 АССОЦИАТИВНЫЕ СВЯЗИ.
Можно ли смоделировать переход от одной темы к другой, как в изображенном выше дереве? Случайное переключение нескольких битов вектора ни к чему не приведет, т.к. паттерны в SDM изолированны огромными областями. В канонической модели радиус притяжения равен 200, поэтому объем отдельной области равен 〖sum〗_(k=1)^(200 ) (〖_k^1000〗) = 10216. Это все еще малая часть 1000-мерного куба. Среди вершин куба только 1 из 1080 лежит в пределах 200 бит сохраненного паттерна.
Для обозначенной задачи можно, используя операцию XOR. Эта операция дает не только расстояния между векторами, но и ориентацию соединяющей линии. Более того, XOR симметрична: u xor v = v xor u, и является собственной обратной функцией: u xor v = w, u xor w = v, v xor w = u.
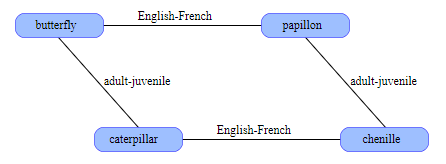
С помощью таких преобразований можно упорядочить информации. В SDM. Допустим, слово butterfly и его французский аналог papillon хранятся случайных векторах. Они не будут близки друг к другу; расстояние между ними с большой вероятностью примерно равна 500 битам. Теперь мы вычисляем XOR этих векторов butterfly papillon; результатом является ещё один вектор, который также можно сохранить в SDM. Этот новый вектор кодирует связь английский-французский. Теперь у нас есть инструмент для перевода. Имея вектор для butterfly, мы выполняем для него XOR с вектором английский-французский и получаем papillon. Тот же трюк работает и в обратном направлении. Такую операцию можно экстраполировать на остальные связи. (рис. 8)
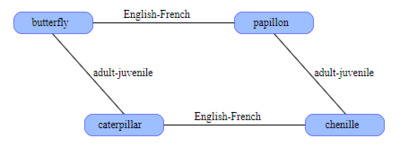
Рис. 8 Организация связей между паттернами в SDM.
При заданном узле и связи операция исключающего или привязывает узел к конкретной позиции где-то в другом месте в гиперкубе. Также здесь узлы и ребра имеют одинаковое представление.
Теперь модель может связывать любые две концепции через любую связь, однако в реальном мире множество связей несимметрично, т. е. не имеют свойства самоинвертируемости. Например, XOR может сказать, что Маша и Миша являются родителями одного ребенка, но не сообщает, кто есть кто. Т. к. соединить возможно только два узла, то если у упомянутых выше несколько детей, то это поставит модель в неприятное положение. Еще одна проблема заключается в том, что граф должен оставаться целостным: если мы захотим добавить узел между двумя связями, для этого придется перезаписывать большую часть схемы.
Часть этой проблемы можно решить при помощи бандлинга – создании базы, в которой записываются пары атрибут-значение. Первый этап заключается в отдельном XOR каждой пары атрибут-значение. Затем векторы, полученные при помощи предыдущей операции, комбинируются, чтобы создать единый суммарный вектор. Выполняя XOR имени атрибута с комбинированным вектором, получается аппроксимация соответствующего значения, ддостаточно близкое, чтобы определить его методом рекурсивных воспоминаний. [1]
2.5 ЗАКЛЮЧЕНИЕ
Однако возникает еще одна проблема - алгоритм никак не может узнать, какие связи доступны для выбора. Связи и атрибуты представлены в форме векторов и хранятся в памяти как и любые другие объекты, поэтому не существует очевидных способов получения этих векторов, если только не знать, какие они на самом деле.
Модель может распознавать знакомые паттерны и сохранять новые, которые будут распознаваться при следующих встречах даже из частичных или повреждённых сигналов. Благодаря связыванию или бандлингу память также может отслеживать связи между парами сохранённых элементов. Но всё, что записывается в память, может быть извлечено только при передаче подходящего сигнала.
Однако мозг человека так работает не так - людям не нужно видеть объект, чтобы вспомнить о ем. Получается, данная модель оборудована ля обслуживания чувств, но не воображения.
3. СЕТЬ ХОПФИЛДА.
Модель разреженной распределённой памяти Пентти Канерва — одна из попыток создания модели человеческой памяти. Это не единственная такая попытка. Более известной альтернативой является подход Джона Хопфилда. – по видимому, наиболее распространенный подход в нейронауке. Сеть Хопфилда очень надежна – эксперименты показывают, что при увеличении количества вышедших из строя нейронов до 50%, вероятность правильного ответа близка к 100%.
3.1 СТРУКТУРА.
Для того, чтобы разобраться, как работает данный подход, необходимо иметь представление об устройстве нейрона.(рис. 9)
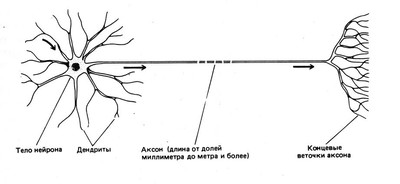
Рис. 9 Строение нейрона.
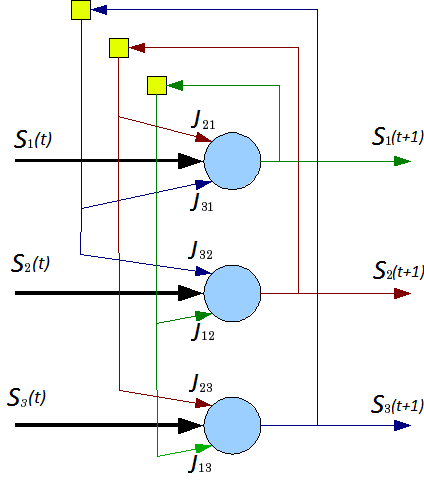
Сеть состоит из N искусственных нейронов, аксон каждого нейрона связан с дендритами остальных нейронов, образуя обратную связь. (рис. 10)
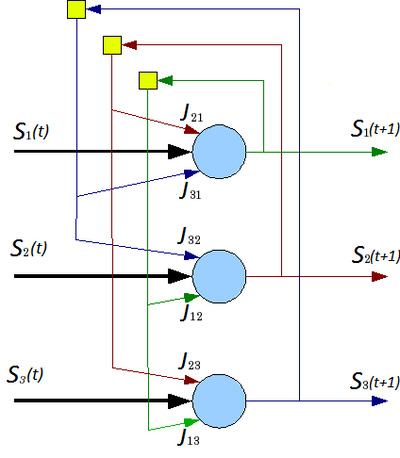
Рис. 10 Архитектура нейронной сети Хопфилда.
Каждый нейрон может находиться в одном из 2-х состояний: +1 и -1. +1 соответствует возбуждению нейрона, - 1 соответствует торможению нейрона. Дискретность состояний нейрона отражает нелинейный, пороговый характер его функционирования и известный в нейрофизиологи как принцип «все или ничего».
Динамика состояния во времени i-ого нейрона в сети из N нейронов Ji,j — матрицей весовых коэффициентов, описывающих взаимодействие дендритов i-ого нейрона с аксонами j-ого нейрона, где Ji,j — матрица весовых коэффициентов, описывающих взаимодействие дендритов i-ого нейрона с аксонами j-ого нейрона.
3.2 ОБУЧЕНИЕ.
В процессе обучения формируется выходная матрица J, которая запоминает m эталонных «образов» — N-мерных бинарных векторов: Sm=(sm1, sm2,...,smN), эти образы выражают отклик системы на входные сигналы, или окончательные значения выходов после серии итераций. Необходимым условием для работы является равенство нулю диагональных элементов (нейроны не могут быть связаны сами с собой), а достаточным – асинхронный режим работы сети.
Матрица взаимодействий хранится на самих нейронах в виде весов при связях нейронов с другими нейронами.
Предположим, что входной сигнал определяется 10 параметрами, тогда нейронная сеть Хопфилда формируется из одного уровня с 10 нейронами. Каждый нейрон связывается с остальными 9-ю нейронами, таким образом в сети образуется 90 связей. Для каждой связи определяется весовой коэффициент. Все веса связей образуют матрицу взаимодействий, которая заполняется в процессе обучения.
Обучение сети входными образами Х_µ^in сводиться к вычислению значений элементов матрицы J_(i,j), то есть к расчету весовых коэффициентов. [2]
4. МОЗГ КАК УЗЕЛ СЕТИ.
Согласно исследованиям, мозг может являться часть сети при помощи определенного интерфейса. Интерфейс установит связь между нейронными связями в мозге и обширным мощным облаком, предоставляя людям доступ к необъятным вычислительным мощностям и огромной базе знаний человеческой цивилизации. [3] Базой для создание такого интерфейса служит надежда на прогресс в области технологии, работающей в молекулярных масштабах. [4]
ЗАКЛЮЧЕНИЕ.
В академических кругах имеет место название «Четвертая промышленная революция», связанное с внедрением ИИ. Такое название возникло в результате инициативы 2011 года, возглавляемой учеными, бизнесменами, политиками, которые определили четвертую промышленную революцию как средство повышения конкурентоспособности обрабатывающей промышленности Германии через усиленную интеграцию «киберфизических систем» в заводские процессы. [5] Как и до этого, изменения охватят разные стороны жизни: от политической системы до того, что вы будете есть на обед.
Поэтому необходимо иметь представление об технологиях, которые вскоре приведут к изменения миропорядка. Как и раньше, промышленные революции возводили страну в статус гегемона, а другие страны довольствовались вторым местом.
СПИСОК ЛИТЕРАТУРЫ
1. Hayes, B. (б.д.). The Mind Wanders https://habr.com/ru/post/419147/.
2. Melnikov, S. (б.д.). Нейронная сеть Хопфилда на пальцах https://habr.com/ru/post/301406/.
3. René Castien, W. D. (б.д.). A Neuroscience Perspective of Physical Treatment of Headache and Neck Pain https://www.frontiersin.org/articles/10.3389/fneur.2019.00276/full.
4. Cloud4Y, Б. к. (б.д.). Через «пару десятилетий» мозг подключат к Интернету https://habr.com/ru/company/cloud4y/blog/448728/.
5. Хель, И. (б.д.). Индустрия 4.0: что такое четвертая промышленная революция? https://hi-news.ru/business-analitics/industriya-4-0-chto-takoe-chetvertaya-promyshlennaya-revolyuciya.html. |
| Категория: Рефераты (курсы КП, ПК, ИТ и Сети) | Добавил: seniornikitatarasoff2012 (20.12.2019)
| Автор: Никита Тарасов
|
| Просмотров: 355
| Рейтинг: 0.0/0 |
Добавлять комментарии могут только зарегистрированные пользователи. [ Регистрация | Вход ] |
|