| Статистика |

Онлайн всего: 1 Гостей: 1 Пользователей: 0 |
|
Сети на кристалле
1. Введение
Вся современная индустрия высоких технологий завязана на высокопроизводительных машинах, которые в большинстве случаев реализованы в виде систем на кристалле. Первоначально производительность таких систем наращивали путем увеличения тактовой частоты работы этой системы. Но ввиду физических ограничений, дальнейшее увеличение частоты стало невозможным.
Тогда для увеличения вычислительной мощности стали применять несколько блоков в одной системе. Так появилось понятие многоядерности. Сейчас существует множество вариаций состава СнК в зависимости от их назначения. Начиная от серверных многоядерных систем, заканчивая мобильными системами на кристалле с набором из множества блоков различного назначения.
Но, с наращиванием числа IP-блоков в системе, остро встает вопрос о коммутации этих блоков. Дело в том, что на протяжении последних нескольких десятилетий основой коммуникации между отдельными IP-блоками чипа служила шина (например AXI шина). Пока блоков было немного, она справлялась, но, когда начало расти число ядер на чипе, эта архитектура исчерпала себя. Шина представляет собой общую среду передачи данных, к которой подключено несколько блоков процессора. В каждый момент времени один блок может передавать данные, а все остальные — получать. Если нескольким блокам нужно передавать одновременно — возникает коллизия, а значит и задержка. При числе ядер больше восьми задержки становятся неприемлемо большими, практически полностью перечёркивая преимущества параллельной работы нескольких ядер.
Решение, которое позволит объединять сотни блоков на одном чипе — это хорошо известная всем сеть с коммутацией пакетов, или Network on Chip (NoC) (рис. 1).
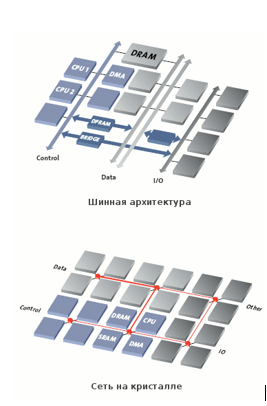
Рис. 1. Сравнение архитектур, основанных на шине и сети на кристалле
2. Архитектура и требования к NoC
В архитектуре NoC каждое ядро или блок процессора соединён с маршрутизатором, через который происходит его общение с другими блоками. Сами маршрутизаторы объединены в сеть, по которой пакеты данных путешествуют от одного блока к другому, так же как пакеты в обычной компьютерной сети. Это значительно упрощает топологию микросхемы и снимает ограничения по масштабированию — в отличие от шины, множество блоков способно общаться одновременно, не мешая друг другу. Компьютерное моделирование и опытные образцы многоядерных процессоров показывают, что при большом количестве ядер такая архитектура превосходит традиционную по многим показателям.
2.1 Требования к NoC
• достаточная пропускная способность для одновременных обменов каждого ядра со всеми банками кэша;
• минимальные задержки между входом пакета в сеть и выходом, чтобы время доступа в кэш оставалось достаточно низким;
• качество обслуживания абонентов сети, то есть ядер, должно удерживаться в некоторых рамках, чтобы работа одних ядер не вызывала простой других;
• соблюдение порядка пакетов между каждой парой узлов (для тех типов пакетов, которые этого требуют), иначе некоторые транзакции приходится задерживать до завершения предыдущих.
Пропускная способность сети в основном определяется её топологией – порядком, в котором соединены каналами её узлы (роутеры), – и шириной этих каналов. Соблюдение порядка пакетов достигается применением детерминированной маршрутизации, то есть использованием только одного маршрута между каждой парой узлов, и FIFO-реализацией всех буферов [1]. Сложной проблемой пока остается минимизация задержек и реализация качества обслуживания, причём задержки становятся проблемой всё более острой из-за уменьшения технологических норм производства кристаллов.
2.2 Существующие варианты топологии сети на кристалле
Из всего многообразия методов построения сетей на кристалле наиболее интересны те, которые хорошо масштабируются и не требуют избыточного количества проводов или специальных возможностей физического проектирования, таких как оптические шины или трёхмерная компоновка. Традиционный подход заключается в равномерном распределении ядер, банков кэша и сетевых роутеров по кристаллу и присоединении одного или нескольких ядер и одного или нескольких банков кэша к каждому роутеру. В этом случае задача сужается до выбора топологии сети (рис. 2) и внутреннего устройства роутеров.
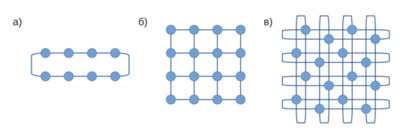
Рис. 2. Топологии: а) кольцо, б) сетка, в) сложенное двумерное кольцо
Самыми распространёнными топологиями являются кольцо (ring, или 1D torus) и двумерная сетка (2D mesh) [2]. Менее известным, но тоже хорошо подходящим для современных чипов вариантом является сложенное двумерное кольцо (folded 2D torus). Наилучшей масштабируемостью и наименьшей длиной путей обладает двумерная сетка (б).
2.3 Способы организации сети
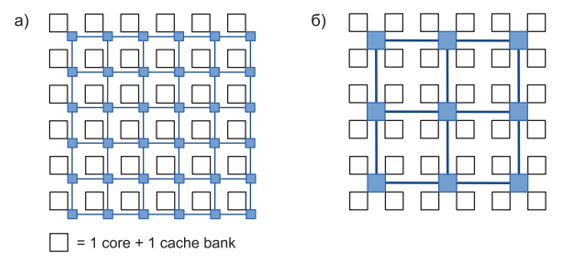
Простейший вариант реализации сети на кристалле, ориентированный на хорошую масштабируемость и минимальные задержки, – плиточная (tiled) организация – заключается в использовании топологии двумерная сетка с подключением одного ядра и одного банка кэша к каждому роутеру (рис. 3а). Однако, если учитывать, что прохождение пакета через каждый роутер включает задержки на его маршрутизацию, арбитраж и прочее, предпочтительнее может оказаться сеть с более крупным шагом и несколькими ядрами, и банками на один роутер (рис. 3б). В любом случае задержки получаются существенно выше идеальных – таких, как если бы все абоненты сети были соединены напрямую.
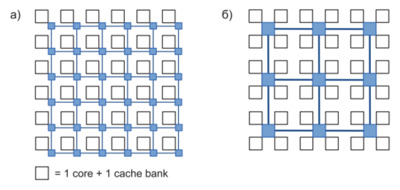
Рис.3. Организация сети: а) плиточная, б) концентрированная
2.4 Улучшение показателей сети
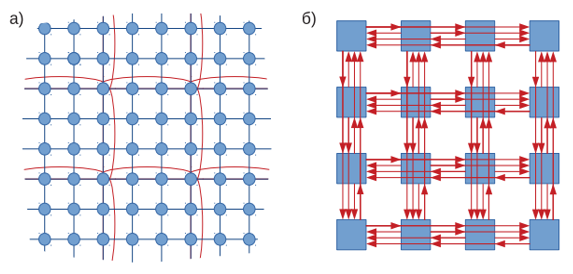
Для уменьшения задержек существует несколько способов: Первый заключается в оптимизации всех стадий конвейера обработки пакета для либо их ускорения, либо выполнения параллельно друг с другом. При этом в каждом роутере всё равно будет некоторая задержка и может увеличиться энергопотребление. Второй подход заключается в реализации экспресс-каналов или их производных. Экспресс-каналы – дополнительные каналы, соединяющие удалённые узлы. Их использование уменьшает среднее количество роутеров, посещаемых пакетами, и таким образом суммарные задержки в роутерах. В больших сетях они могут быть объединены в дополнительную крупную сетку (рис. 4а). Производной от обычных экспресс-каналов является MECS – многоточечные (multidrop) экспресс-каналы, проходящие мимо нескольких узлов так, что пакет может передаваться из первого узла в любой другой (рис. 4б). Нескольких таких каналов на каждую строку и столбец сети достаточно, чтобы все пакеты передавались только по ним и максимум в два шага, что приближает задержки к минимально возможным [2].
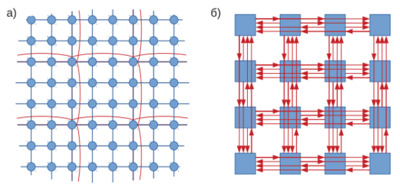
Рис.4. Экспресс-каналы: а) обычные, б) MECS
Кроме того, для увеличения полосы пропускания учеными из MIT был придуман алгоритм виртуального обхода (virtual bypassing) и сигналы с малой амплитудой (low-swing signaling).
Принцип работы такого алгоритма заключается в том, что обычный маршрутизатор сохраняет полученный пакет в буфер, анализирует его заголовок и решает, куда его отправить дальше. Virtual bypassing позволяет передать пакет практически без задержек, за счёт того, что заголовок посылается заранее, и коммутатор успевает сделать нужные переключения цепей к тому моменту, как придёт тело пакета. Таким образом, пакет идёт без остановок, минуя буфер. Low-swing signaling — это уменьшение разницы между напряжениями 0 и 1 в проводнике, за счёт чего удалось дополнительно сократить энергопотребление. В сумме эти усовершенствования поднимают пропускную способность и экономичность разрабатываемой сети более чем в полтора.
Кроме улучшения таких характеристик, как энергопотребление и скорость, архитектура NoC даёт ещё одно важное преимущество. Она легко позволяет объединять не только однородные ядра, но и вообще любые блоки на одном чипе. Как и в компьютерных сетях, физический и транспортный уровни работают одинаково для любых типов данных и протоколов. Можно без особых проблем поставить на место одного или нескольких из универсальных вычислительных ядер любой другой IP-блок, например, графическое ядро, специализированный сигнальный процессор или контроллер какого-либо устройства. И, так же, как и в сетях, можно реализовать поддержку Quality of Service на уровне чипа, что может быть полезно для систем реального времени и виртуализации.
3. NoC в реальных чипах.
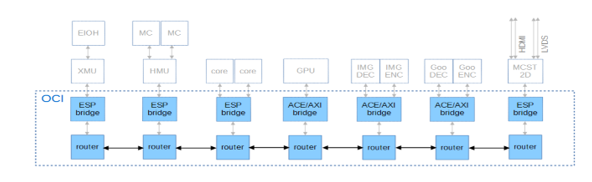
Для соединения множества различных устройств на верхнем уровне микропроцессора — процессорных ядер, HMU, XMU, GPU, кодеков — требуется сложная сеть, умеющая передавать пакеты различных размеров и типов. При этом она должна обладать достаточной пропускной способностью, низкими задержками и уметь распределять пропускную способность узких мест системы таким образом, чтобы соблюдались приоритеты между потоками, и между потоками одного приоритета распределение было достаточно оптимальным, или честным.
3.1 Распределенный одномерный коммутатор.
Под каждый проект сеть выбирается исходя из необходимых требований. С учётом особенностей одного из проектов АО МЦСТ в качестве сети была выбрана топология 1D mesh (рис.5), разделённая на несколько слоёв для разных размеров пакетов, поддерживающая произвольное число виртуальных каналов, два уровня приоритета и по логическому устройству соответствующая распределённому коммутатору с отдельными очередями для пакетов разных типов.
Верхний модуль сети включает в себя верхние модули роутеров и модули-переходники между ними и абонентами. Его интерфейсы соответствуют интерфейсам подключаемых устройств. Верхний модуль роутера включает в себя роутеры разных слоёв сети, интерфейсы которых одинаковы с точностью до значений параметров. Между роутерами могут быть вставлены проходные регистры, в произвольном количестве.
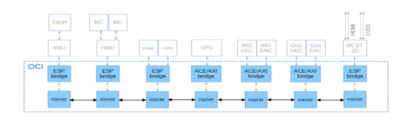
Рис.5. Сеть-на-кристалле и структура её окружения в одном из проектов семейства Эльбрус
3.2 Плиточный трехмерный коммутатор
Общепринятыми решениями для многоядерных систем являются топологии кольца или нескольких колец. Если разрабатываемый продукт в своем составе имеет одинаковые процессорные ядра, то разумным выбором будет концентрированная топология сети, так как в этом случае она обеспечивает лучшие времена доступа и более высокую пропускную способность.
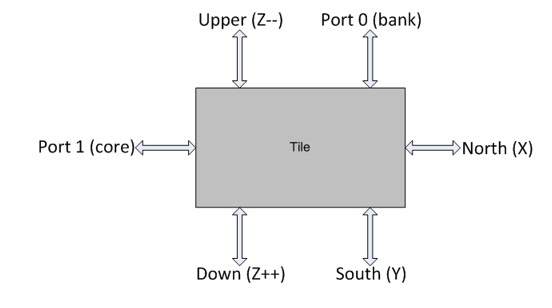
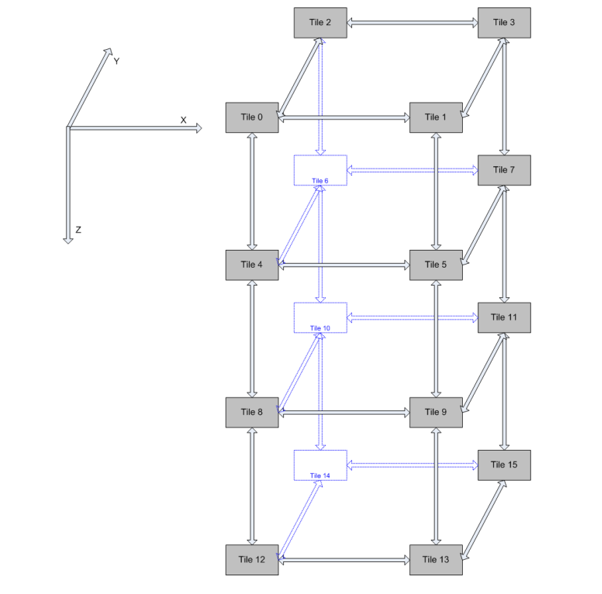
Наиболее удобным является способ проектирования с использованием tile. Узел Tile (рис.6) – это единица сети, включающая в себя коммутатор и роутер, к которой подключаются абоненты сети. Каждый абонент подключается только к определенному узлу, на прямую между собой абоненты соединяться не могут.
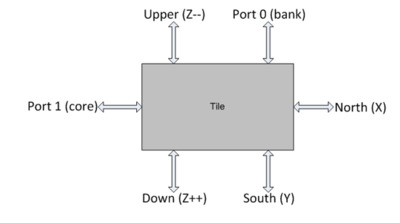
Рис.6. Устройство узла Tile
К каждому узлу могут подключаться два устройства. По умолчанию к порту под номером 0 подключается банк кэша третьего уровня, а к порту под номером 1 - процессорное ядро. Но возможен и такой вариант, что к этим портам могут подключаться и другие абоненты сети (такие как HMU). При этом возникает сложность в маршрутизации, так как другие компоненты системы должны узнать об особом абоненте сети.
Так в системе, обладающей 16-ю процессорными ядрами, будет 16 узлов tile, к каждому из которых подключены один банк кэша и одно процессорное ядро (рис. 7). При этом такое подключение позволит расположить кэш память в одном месте на кристалле, что заметно упростит проектировку системы.
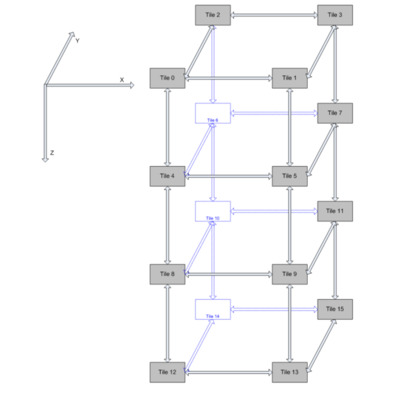
Рис.7. Структура сети на кристалле в многоядерной системе
4. Будущее применения сетей в микропроцессорных системах
В современных реалиях, когда технологические нормы производства становятся все меньше и меньше, изготавливать большие чипы становится все дороже и дороже. Для разработчиков коммерческой продукции серьезным вопросом является получение наибольшей прибыли при удержании все той же планки качества продукции.
Решение было найдено в применении чиплетов [3] – маленьких кремниевых кристаллов, включающих в себя различные процессорные компоненты. Но при таком подходе резко встает вопрос о коммутации таких мини-кристаллов в полнофункциональную систему.
В разных компаниях существуют различные решения этого вопроса
4.1 Infinity fabric
Infinity fabric - это запатентованная система межсоединений, которая облегчает передачу данных по всем связанным компонентам, а так же заметно упрощает управление ими. Эта архитектура используется в последних микроархитектурах AMD как для ЦП (т.е. Zen), так и для графики (например, Vega), а также для любых других дополнительных ускорителей, которые они могут добавить в будущем. Впервые данная система была представлена в апреле 2017 года
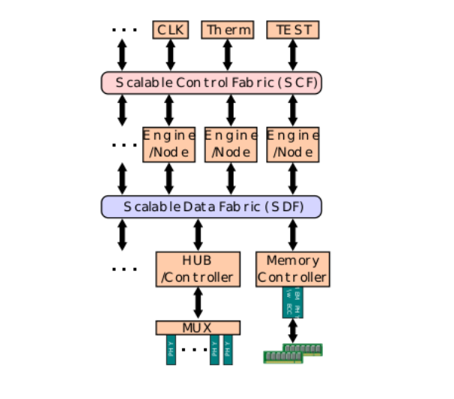
Infinity Fabric состоит из двух отдельных плоскостей связи - Infinity Scalable Data Fabric (SDF) и Infinity Scalable Control Fabric (SCF) (рис. 8). SDF - это плоскость передачи данных. Все данные с ядер и других периферийных устройств (например, контроллеров памяти и концентраторов ввода / вывода) направляются через SDF. Ключевой особенностью связной структуры данных является то, что она не ограничивается одним кристаллом и может распространяться на несколько кристаллов, а также на несколько сокетов по каналам PCIe. Также нет ограничений на топологию узлов, соединенных по матрице, связь может осуществляться непосредственно между узлами. SCF - это дополнительная плоскость, которая обрабатывает передачу множества разных сигналов управления системой - это включает в себя такие вещи, как управление температурой и питанием, тесты, безопасность и IP сторонних производителей. Благодаря этим двум плоскостям AMD может эффективно масштабировать многие базовые вычислительные блоки [4].
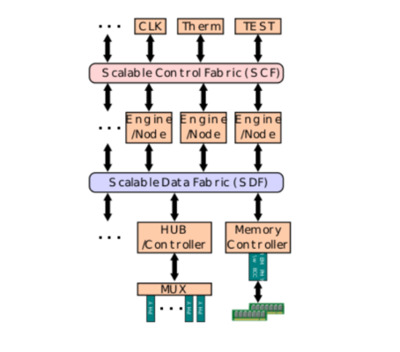
Рис.8. Общая структура Infinity fabric
В новом поколении процессоров AMD с микроархитектурой Zen 2 ключевой особенностью стало применение сети Infinity fabric с целью увеличения количества процессорных ядер в системе. Располагая на одной подложке несколько отдельных небольших кристаллов с процессорными ядрами, построенных по новейшему технологическому процессу (рис. 9), AMD добились не только значительного увеличения мощности такой системы, но и хорошей системы ценообразования - что немаловажно на коммерческом рынке.

Рис.9. Пример подложки с чиплетами AMD
4.2. Межкомпонентная кремниевая сеть
Тенденции в развитии электроники, в настоящее время, идут в сторону миниатюризации систем и увеличения их производительности. И сегодня производительность некоторых компонентов приближается к такому значению, когда задержки по распространению сигналов в среде становятся весьма существенными.
Все компоненты в вычислительных машинах соединяются при помощи материнской платы. Сигналы в такой плате распространяются по проводникам, которые наносятся на текстолит.
Идея межкомпонентной кремниевой сети (рис. 10) состоит в том, чтобы избавиться от материнской платы заменив ее кремниевой подложкой. Такой подход позволил бы создавать как системы меньшего размера и веса, пригодные для носимой электроники и других ограниченных в размерах устройств, так и невероятно мощные высокоскоростные компьютеры, способные запихнуть вычислительные мощности десятка серверов в кремниевую подложку размером с обеденную тарелку [5].
Метод компоновки систем от AMD, который основан на применении чиплетов, является очень хорошей предпосылкой к развитию такой сети. Infinity fabric, благодаря своей гибкости, сможет весьма успешно послужить основой для большой кремниевой сети и соединить огромное количество различных компонентов.

Рис.10. Возможный вид межкомпонентной кремниевой сети
5. Заключение
Сеть на кристалле является не менее важным элементом современного процессора, чем его вычислительное ядро. Дальнейшее развитие вычислительной техники, без хорошего проектирования NoC, будет практически невозможным. Так как в настоящее время мы подошли к физическим ограничениям увеличения производительности отдельного ядра, дальнейшее наращивание мощности процессора идет путем увеличения количества ядер в системе. И для эффективной работы многоядерной системы необходима правильно разработанная сеть, которая сможет грамотно управлять трафиком.
Помимо всего прочего, эта разработка может послужить резким толчком для миниатюризации и удешевления вычислительных систем.
Список используемых источников:
1. http://mcst.ru/files/566b1d/ad0cd8/50cf01/.../nedbailo_1.pdf - Ю.А.Недбайло. Разработка сети на кристалле перспективных микропроцессоров серии Эльбрус (тез. доклада)
2. https://mipt.ru/upload/medialibrary/9d4/19_...ilo_151_163.pdf - Ю.А.Недбайло. Разработка сети на кристалле для перспективных многоядерных микропроцессоров, статья (2017)
3. https://habr.com/ru/post/429166/ - Мультикристалл: от истории до спекуляций о будущем (2018)
4. https://en.wikichip.org/wiki/amd/infinity_fabric - Infinity Fabric (IF) – AMD
5. https://habr.com/ru/post/471532/ - Прощай, печатная плата; здравствуй, межкомпонентная кремниевая сеть (2019) |
| Категория: Рефераты (курсы КП, ПК, ИТ и Сети) | Добавил: superbernikita (23.12.2019)
| Автор: Бер Н.А.
|
| Просмотров: 343
| Рейтинг: 0.0/0 |
Добавлять комментарии могут только зарегистрированные пользователи. [ Регистрация | Вход ] |
|