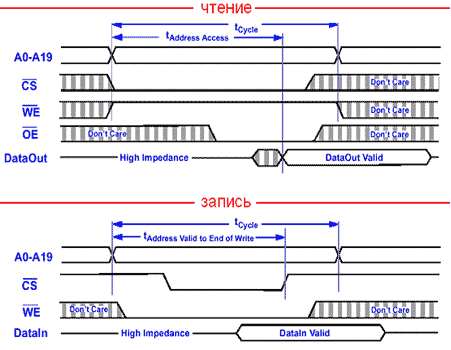
Временные диаграммы чтения/записи
Временные диаграммы чтения/записи статической памяти практически ничем не отличаются от аналогичных им диаграмм микросхем динамической памяти (что и неудивительно, т. к. интерфейсная обвязка в обоих случаях схожа).
Цикл чтения
Цикл чтения начинается со сброса сигнала CS (Chip Select - Выбор Чипа) в низкое состояние, давая понять тем самым микросхеме, что чип "выбран" и сейчас с ним будут работать (и работать будут, и прорабатывать!).
К тому моменту, когда сигнал стабилизируется, на адресных линиях должен находиться готовый к употреблению адрес ячейки (т.е. номер строки и номер столбца), а сигнал WE должен быть переведен в высокое состояние (соответствующее операции чтения ячейки). Уровень сигнала OE (Output Enable - разрешение вывода) не играет никакой роли, т.к. на выходе пока ничего не содержится, точнее выходные линии находятся в, так называемом, высоко импедансом состоянии.
Спустя некоторое время (tAddress Access), определяемое быстродействием управляющей логики и быстротечностью переходных процессорах в инверторах, на линиях выхода появляются долгожданные данные, которые вплоть до окончания рабочего цикла (tCycle) могут быть непосредственно считаны. Обычно время доступа к ячейке статической памяти не превышает 1 - 2 нс., а зачастую бывает и меньше того!
Цикл записи
Цикл записи происходит в обратном порядке. Сначала мы выставляем на шину адрес записываемой ячейки и одновременно с этим сбрасываем сигнал WE в низкое состояние. Затем, дождавшись, когда наш адрес декодируется, усилиться и поступит на соответствующие битовые линии, сбрасываем CS в низкий уровень, приказывая микросхеме подать сигнал высокого уровня на требуемую линию row. Защелка, удерживающая триггер, откроется и в зависимости от состоянии bit-линии, триггер переключится в то или иное состояние. 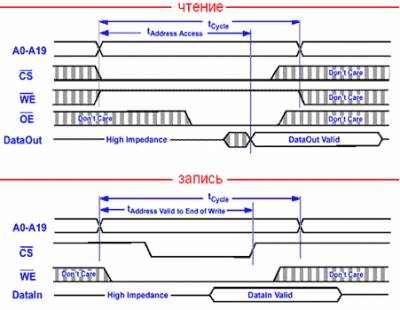
Рис. 11. Временные диаграммы чтения/записи асинхронной статической памяти Типы статической памяти
Существует как минимум три типа статической памяти: асинхронная (только что рассмотренная выше), синхронная и конвейерная. Все они практически ничем не отличаются от соответствующих им типов динамической памяти (см. статью "Устройство и принципы функционирования оперативной памяти"), поэтому, во избежание никому не нужного повторения ниже приведено лишь краткое их описание.
Асинхронная статическая память
Асинхронная статическая память работает независимо от контроллера и потому, контроллер не может быть уверен, что окончание цикла обмена совпадет с началом очередного тактового импульса. В результате, цикл обмена удлиняется по крайней мере на один такт, снижая тем самым эффективную производительность. "Благодаря" последнему обстоятельству, в настоящее время асинхронная память практически нигде не применяется (последними компьютерами, на которых она еще использовались в качестве кэша второго уровня, стали "трешки" - машины, построенные на базе процессора Intel 80386).
Синхронная статическая память
Синхронная статическая память выполняет все операции одновременно с тактовыми сигналами, в результате чего время доступа к ячейке укладывается в один-единственный такт. Именно на синхронной статической памяти реализуется кэш первого уровня современных процессоров.
Конвейерная статическая память
Конвейерная статическая память представляет собой синхронную статическую память, оснащенную специальными "защелками", удерживающими линии данных, что позволяет читать (записывать) содержимое одной ячейки параллельно с передачей адреса другой.
Так же, конвейерная память может обрабатывать несколько смежных ячеек за один рабочий цикл. Достаточно передать лишь адрес первой ячейки пакета, а адреса остальных микросхема вычислит самостоятельно, - только успевай подавать (забирать) записывание (считанные) данные!
За счет большей аппаратной сложности конвейерной памяти, время доступа к первой ячейке пакета увеличивается на один такт, однако, это практически не снижает производительности, т.к. все последующие ячейки пакета обрабатываются без задержек.
Конвейерная статическая память используется в частности в кэше второго уровня микропроцессоров Pentium-II и ее формула (см. статью "Устройство и принципы функционирования оперативной памяти Формула памяти") выглядит так: 2 - 1 - 1 - 1. Часть 2. Перспективные виды памяти
Сегодня все крупные игроки полупроводниковой отрасли задумываются над своим «посткремниевым» будущим, а некоторые уже делают серьёзные шаги в этом направлении.
Ниже представлены некоторые из наиболее интересных технологий. 2.1 IRAM
Дэвид Паттерсон – известный американский ученый, удостоенный за заслуги в изобретении новых технологий (в том числе технологии RISC) многочисленных наград от ACM (Association for Computing Machinery), IEEE. В настоящее время он занимается исследованиями и разработкой первых микропроцессоров с IRAM-архитектурой. Паттерсон считает, что IRAM принесет еще больше перемен в электронику, чем в свое время RISC-архитектура.
Сегодня микропроцессоры и динамическая память (DRAM) изготавливаются в виде отдельных микросхем. Две тенденции заставляют пересмотреть эту традицию. Во-первых, разрыв в быстродействии между процессором и DRAM ежегодно увеличивается на 50%. Во-вторых, применение микросхем DRAM становится затруднительным из-за гигантского объема (который ежегодно увеличивается на 60%) информации, который требуется хранить в памяти. В разумной RAM, или IRAM (Intelligent Random Access Memory), процессор и память размещаются на одном чипе, благодаря чему снижается время доступа и увеличивается пропускная способность памяти. Кроме того, снижается расход электроэнергии и потребная площадь на системной плате, а также расширяется поле для выбора организации DRAM.
Поместить процессор и DRAM на одном чипе – гораздо более удобно, чем увеличивать имеющуюся на процессоре SRAM, так как DRAM приблизительно в двадцать раз более компактна. (Это отношение больше, чем отношение количества транзисторов ячеек, потому что в DRAM емкость (конденсатор) имеет трехмерную структуру, что сокращает размер ячейки памяти.) Таким образом, IRAM содержит намного больше ячеек памяти на чипе, чем SRAM.
Размещение динамической памяти вместе с процессором на одном чипе дает много выгод в производительности и энергопотреблении. Время доступа к памяти сокращается в 5-10 раз, потребляемая мощность - в 2-4 раза, пропускная способность увеличивается в 50-100 раз. Трудно посчитать экономию за счет уменьшения используемой площади печатной платы и устранения избыточной памяти. Перспективы, которые открывает IRAM, основаны не на экзотической, непроверенной технологии. За последние двадцать лет было выполнено множество работ, благодаря которым и появилась архитектура IRAM.
Вероятно малая популярность IRAM объясняется малым объемом памяти по сравнению с тем, который может быть реализован на DRAM. Однако объем памяти на кристалле увеличивается примерно на 60% в год. Самый лучший сценарий для внедрения IRAM - это применение в графических картах, которые требуют приблизительно 10 Мбит, а также в видеоиграх и PDA, которым нужно около 32 Мбит памяти. Когда объем IRAM достигнет 128-256 Мбит, она начнет применяться в мобильных PC и сетевых компьютерах. Успех в этих приложениях убедит изготовителей микропроцессоров включить DRAM в кристалл CPU или изготовителей DRAM - интегрировать процессоры в чип памяти.
Таким образом, IRAM может изменить характер полупроводниковой промышленности. Из нынешней, разделенной на два лагеря - CPU и DRAM, - могла бы сформироваться единая отрасль. Изготовители микропроцессоров могли бы изготовлять DRAM в промышленных количествах, как сегодня микросхемы SRAM. С другой стороны, производители DRAM вполне могут освоить выпуск микропроцессоров. Оба варианта допустимы. Первый - устроит производителей, стремящихся к выпуску более сложной и технологичной продукции, второй - может привлечь компании, желающие выпускать массовую дешевую продукцию. 2.2 Trigate (NMOS, PMOS) 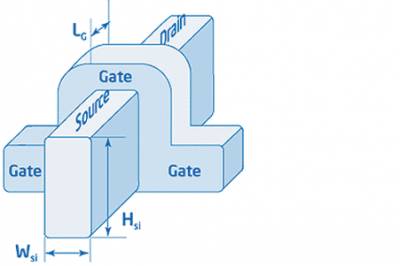
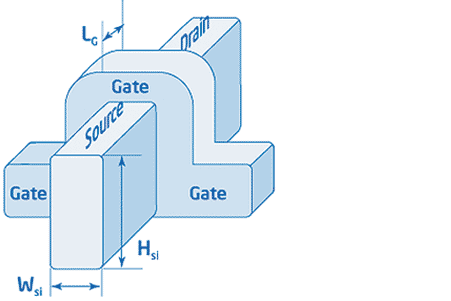
Рис. 12 Чтобы обеспечить соответствие закону Мура и размещать на кристалле все больше транзисторов, полупроводниковая промышленность продолжает внедрять технологические инновации, направленные на уменьшение размеров транзисторов. Однако, несмотря на развитие технологий будущего, уменьшение размеров транзисторов становится все более проблематичным, в частности из-за ухудшения эффектов коротких каналов и возрастания паразитных утечек при уменьшении размеров затвора. Утечка как транзистора в закрытом состоянии (возрастающая при уменьшении размеров затвора), так и диэлектрика затвора (возрастающая при уменьшении толщины слоя диэлектрика затвора) вызывает увеличение рассеиваемой мощности при масштабировании.
Для решения проблемы утечки транзисторов в закрытом состоянии в 2002 году корпорация Intel разработала первый в мире транзистор CMOS tri-gate, в котором применялась новаторская трехмерная конструкция затвора, позволяющая повысить управляющий ток и снизить ток утечки транзистора в закрытом состоянии. В результате был создан непланарный транзистор, который обеспечивает увеличение управляющего тока на 30% для транзисторов NMOS и на 60% для транзисторов PMOS по сравнению с оптимизированными передовыми 65-нм планарными транзисторами при том же уровне утечки в закрытом состоянии. 
Рис. 13 С уменьшением размеров транзисторов паразитные токи утечки и рассеяние мощности становятся серьезными проблемами. Объединив новаторскую конструкцию трехмерных транзисторов tri-gate с передовыми полупроводниковыми технологиями, такими как напряженный кремний и затвор high-k/metal, корпорация Intel создала инновационный подход для решения проблем утечки тока и повышения эксплуатационных характеристик полупроводниковых устройств.
Комплексные транзисторы tri-gate CMOS будут играть важнейшую роль в концепции энергосберегающей производительности корпорации Intel, так как они имеют меньший ток утечки и потребляют меньше электроэнергии по сравнению с планарными транзисторами.
Благодаря тому что транзисторы tri-gate позволяют существенно повысить производительность и эффективность использования электроэнергии, они обеспечивают возможность дальнейшего уменьшения размеров кремниевых транзисторов. Транзисторы tri-gate могут стать основным компонентом микропроцессоров в будущем. Эту технологию можно применять в экономичном, крупносерийном производственном процессе по созданию высокопроизводительной и энергосберегающей продукции. 2.3 Z-RAM
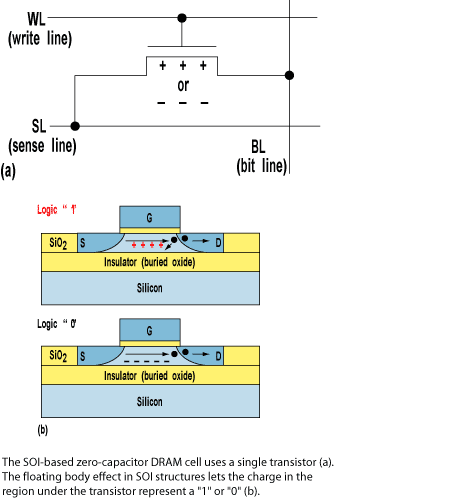
Еще одной перспективной технологией явлеятся z-ram разработанная компанией Innovative Silicon. В качестве конденсатора используется затвор полевого транзистора, отделенный от канала слоем диэлектрика. Основным преимуществом подобной памяти является высокая компактность ячейки памяти - ее размер меньше в пять раз по сравнению с SRAM и в два раза - со стандартной DRAM памятью. Еще одним плюсом Z-RAM является возможность использования существующего оборудования и материалов при производстве чипов - при изготовлении Z-RAM используется SOI техпроцесс (кремний-на-изоляторе), который и применяет AMD для производства своих чипов.
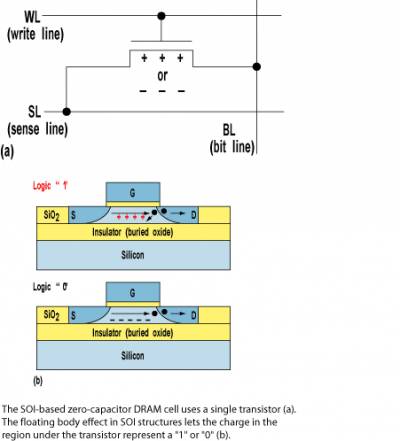
Рис. 14 В планы AMD входит использование Z-RAM в качестве кэш-памяти в будущих моделях микропроцессоров, что позволит значительно увеличить объем "кэша", а вместе с ним и производительность чипов. На данный момент AMD изучает возможность использования новой памяти при производстве чипов. Точные сроки введения подобных изделий в массовое производство пока не установлены.
2.4 AMD
На снимках ниже - тестовая пластина с памятью типа SRAM, изготовленной по нормам 28 нм. 
Рис. 15 
Рис. 16 
Рис. 17
Предложить заказчикам выпуск продукции по массовому 28-нанометровому техпроцессу GlobalFoundries(подразделение AMD) собирается в начале 2010 года, рассчитывая выйти на полномасштабное производство позже в том де году. Выигрыш в терминах размера кристалла и энергопотребления, обеспечиваемый переходом на нормы 28 нм, еще более значителен, чем при переходе на нормы 32 нм, поэтому 28-нанометровый техпроцесс является особенно привлекательным для производства GPU. В этой области GlobalFoundries надеется опередить TSMC. Список использованной литературы
1. http://ru.wikipedia.org/ - Википедия, свободная энциклопедия.
2. Яворский Б.М., Пинский А.А. Основы физики, т.т. 1-2. - М.: ФИЗМАТЛИТ, 2000.
3. Материалы сайта http://news.ferra.ru/hard/2006/01/25/55589/?print=1 - Новая память Z-RAM заменит SRAM в чипах AMD
4. Материалы сайта http://offline.computerra.ru/1998/243/989/ - Доводы в пользу IRAM.
5. Материалы сайта http://www.compress.ru/Archive/CP/2006/10/56/ - Интегрированные транзисторы CMOS tri-gate.
6. Материалы сайта http://www.ixbt.com/news/all/index.shtml?11/99/37 - GlobalFoundries продемонстрировала пластину с чипами, изготовленными по нормам 28 нм.
7. Материалы сайта http://www.citforum.ru/book/optimize/sdram.shtml - Принципы функционирования SRAM.
8. Материалы сайта http://www.homepc.ru/offline/print/2006/123/288841/ - На твердую память. |