| Статистика |
Онлайн всего: 1 Гостей: 1 Пользователей: 0 |
|
Азбука диагностики Сетей
Вопросы терминологии.
Чтобы правильно организовать диагностику своей сети, вы должны знать, какую задачу какими средствами предпочтительнее решать.
Многообразие имеющихся на рынке диагностических средств можно классифицировать по двум основным признакам.
- Средство предназначено для диагностики сети или для тестирования сети.
- Средство предназначено для реактивной диагностики или для упреждающей диагностики.
Часто термины "диагностика" и "тестирование" употребляются как синонимы. Это не совсем верно. Как правило, под диагностикой сети принято понимать измерение характеристик работы сети в процессе ее эксплуатации (без остановки работы пользователей). Диагностикой сети является, в частности, измерение числа ошибок передачи данных, степени загрузки (утилизации) ресурсов сети или времени реакции прикладного ПО, которую администратор сети должен осуществлять ежедневно.
Диагностика бывает двух типов: упреждающая (proactive) и реактивная (reactive). Упреждающая диагностика должна проводиться в процессе эксплуатации сети ежедневно. Основная цель упреждающей диагностики — предотвращение сбоев в работе сети. Реактивная диагностика выполняется, когда в сети уже произошел сбой и надо быстро локализовать источник и выявить причину.
Если вы хотите проверить соответствие качества кабельной системы требованиям стандартов, определить максимальную пропускную способность вашей сети или оценить время реакции прикладного ПО при изменении параметров настройки коммутатора или ОС, то такие измерения можно сделать только при отсутствии в сети работающих пользователей. В этом случае правильно употреблять термин "тестирование" сети. Таким образом, тестирование сети — это процесс активного воздействия на сеть с целью проверки ее работоспособности и определения потенциальных возможностей по передаче сетевого трафика.
Тестирование можно условно разделить на несколько видов в зависимости от цели, ради которой оно проводится. Это тестирование кабельной системы сети на соответствие стандартам TIA/EIA TSB-67; стрессовое тестирование конкретных сетевых устройств с целью проверки устойчивости их работы при различных уровнях нагрузок и различных типах сетевого трафика; тестирование ПО, в частности для определения его требований к пропускной способности сетевых ресурсов (к характеристикам канала связи, сервера и т. п.); стрессовое тестирование сети (конкретных сетевых конфигураций) с целью выявления "скрытых дефектов" в оборудовании и "узких мест" в архитектуре сети, а также с целью определения пороговых значений трафика, допустимых в данной сети.
Тестирование прикладного ПО с целью определения требований к пропускной способности сетевых ресурсов проводят (во всяком случае должны проводить) компании-разработчики ПО. Такое тестирование осуществляется в рамках комплексной проверки ПО перед выпуском его на рынок и называется тестированием на соответствие качеству (Quality Assurance Test, QAT). К сожалению, отечественные разработчики занимаются этим очень редко. Более того, разрабатывая прикладное ПО, многие вообще не задумываются об эффективности его работы в сети. Но это тема отдельной статьи (мы планируем сделать ее следующей в данном цикле).
Стрессовое тестирование сетевых устройств обычно проводится независимыми специализированными лабораториями. Примерами таких лабораторий являются организации LANQuest (http://www.lanquest.com) и Data Communications (http://www.data.com). Обычно стрессовое тестирование устройств проводится с целью проверки заявленных технических характеристик и выявления различного рода дефектов. Перед принятием окончательного решения о покупке какого-то устройства мы советуем познакомиться с результатами стрессового тестирования этого устройства в независимой лаборатории.
Мы же кратко рассмотрим только один вид тестирования — стрессовое тестирование сети. Именно этот вид тестирования, с нашей точки зрения, должен представлять наибольший интерес для администраторов сетей и системных интеграторов.
Стрессовое тестирование сети.
Основное отличие стрессового тестирования сети от тестирования устройств (в лабораторных условиях) заключается в том, что его задача состоит в проверке работоспособности уже купленных вами устройств в конкретных условиях эксплуатации (для конкретной кабельной системы, уровня шума, качества питающего напряжения, используемого оборудования и ПО и т. п.).
Как и тестирование кабельной системы, стрессовое тестирование сети должно быть обязательной процедурой перед вводом сети в промышленную эксплуатацию. В настоящее время это делается крайне редко. Единственным обнадеживающим моментом остается тот факт, что еще несколько лет назад и кабельная система очень редко тестировалась перед вводом сети в эксплуатацию.
Цель стрессового тестирования сети состоит, во-первых, в выявлении дефектов оборудования и архитектуры сети и, во-вторых, в определении границ применимости существующей архитектуры сети.
Замечание №1. Стрессовое тестирование сети всегда должно предшествовать постановке сети на обслуживание. Результаты стрессового тестирования сети являются ориентиром при проведении упреждающей диагностики.
Чтобы сделать правильные выводы о состоянии сети по результатам наблюдения за параметрами ее работы с помощью средств диагностики, вы должны знать, каковы максимально допустимые значения этих параметров именно для вашей сети. Достоверные выводы о причинах неадекватного поведения сети сделать очень сложно, если вы точно не знаете, какова допустимая утилизация канала связи для обеспечения нормального времени реакции эксплуатируемого прикладного ПО или как пропускная способность вашего коммутатора или сервера зависит от длины кадров, типа протоколов, числа широковещательных и групповых пакетов, режима коммутации и т. п.
Замечание №2. Основными инструментами для стрессового тестирования сети являются генераторы трафика, анализаторы сетевых протоколов и стрессовые тесты.
Генераторы трафика могут быть чисто программными или программно-аппаратными. Суть работы генератора трафика заключается в том, что, задавая параметры, направление и интенсивность трафика, вы создаете в сети дозируемую нагрузку с определенными параметрами трафика (длиной кадров, типом протокола, адресом источника и приемника и т. п.).
Примером программного генератора трафика является Frame Thrower компании LANQuest. Он работает на обычном ПК и может генерировать трафик для сетей Ethernet, Token Ring, FDDI, ATM. Примером аппаратного генератора трафика является устройство PowerBits компании Alantec для сетей Ethernet и FDDI. Генераторы трафика встраиваются во многие анализаторы сетевых протоколов, например в Sniffer компании Network Associates, DA-30 компании Wandel&Goltermann, HP Analyzer компании Hewlett-Packard, Observer компании Network Instrumens и др.
На Рисунке 1 показаны параметры, задаваемые в генераторе трафика программы Observer.
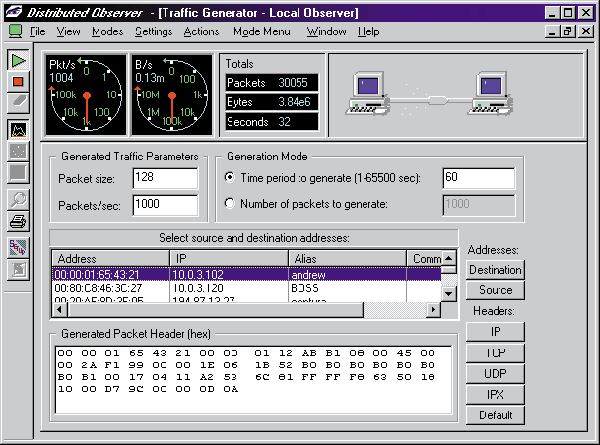
Рисунок 1. Параметр Packets/sec задает интенсивность генерируемого трафика. Параметр Packet size задает размер генерируемых кадров. Параметр Destination задает МАС-адрес, куда будет производиться генерация. Параметры IP/TCP/UDP/IPX определяют формат генерируемых данных.
Стрессовые тесты — это специальное программное обеспечение для эмуляции работы в сети различных приложений. Стрессовыми такие тесты называются потому, что при их работе в сети создается высокая нагрузка. Иногда они называются инструментарием для тестирования клиент-серверных приложений.
Примерами стрессовых тестов для эмуляции работы с файлами в сети являются MS-Test компании Microsoft, NetBench и ServerBench компании Ziff-Davis, Perform3 компании Novell, FTest компании "ПроЛАН". Примерами более сложных стрессовых тестов для эмуляции работы в сети конкретных приложений могут служить EMPOWER компании Performix, QA Partner компании Segue, AutoUser Simulater компании "ПроЛАН". В данной статье мы рассмотрим, как можно провести стрессовое тестирование сети с помощью распределенного программного анализатора протоколов Distributed Observer компании Network Instruments и стрессового теста типа программы FTest компании "ПроЛАН" или Perform3 компании Novell на примере тестирования гипотетической сети, изображенной на Рисунке 2. Предлагаемая в данной статье методика не является "истиной в последней инстанции", а служит лишь иллюстрацией возможных методов решения описанных выше задач.

Рисунок 2. Центральный анализатор протоколов подключается к зеркальному порту коммутатора. Удаленный агент анализатора протоколов, расположенный в домене А, настраивается на генерацию ТСР-трафика на МАС-адрес станции-"приемника", в домене MAIN. Агент анализатора протоколов из домена MAIN настраивается на генерацию трафика во встречном направлении. Аналогично настраиваются генераторы трафика по всем остальным портам коммутатора. На фоне генерации трафика запускается работа приложения BOSS.
Организация стрессового тестирования.
Предположим, что установленный в центре сети коммутатор имеет порты Fast Ethernet и Ethernet, причем серверы MAIN и BASE подключены к первым, а концентраторы и пользователи — ко вторым. Предположим также, что в сети используются различные типы протоколов, такие, как TCP/IP, NetBEUI/
NetBIOS и IPX/SPX. Для простоты описания эксперимента мы будем считать, что центральный коммутатор имеет зеркальный порт (mirror port), куда можно перенаправлять трафик с любого порта центрального коммутатора для его анализа.
Замечание №3. Первым этапом стрессового тестирования сети является оценка работоспособности основных устройств в условиях высоких пиковых нагрузок. Тестированию целесообразно подвергать не все устройства, а только те, что имеют важное значение с точки зрения пропускной способности и надежности сети. Мы обычно называем этот этап тестирования "калибровкой главного устройства сети".
Поскольку в сети, изображенной на Рисунке 2, надежность центрального коммутатора определяет надежность всей сети, то мы должны знать, какова способность центрального коммутатора выдерживать высокие пиковые нагрузки и какова при этом будет поддерживаемая скорость для разного типа трафика. Основной интерес представляет не само значение пропускной способности, выраженное в Мбит/с, а возможность потери кадров коммутатором. Значение совокупной пропускной способности устройства (aggregate bandwidth), которое производители приводят в документации, мало информативно, так как документация обычно умалчивает о том, при каких условиях и для какого типа трафика проводились измерения. Наверняка эти условия были наилучшими для данного устройства.
Кроме этого, важное значение имеет оценка вероятности того, что при определенных условиях какой-то порт коммутатора отключится из-за высокой нагрузки (что иногда и происходит), и коммутатор необходимо будет перезапустить в "холодном режиме".
Чтобы получить достоверные результаты, эксперимент по стрессовому тестированию сети должен быть правильно спланирован. Одним из возможных сценариев является описанный ниже. Центральный анализатор протоколов (Distributed Observer) подключается к зеркальному порту коммутатора, куда по очереди перенаправляется трафик с разных доменов сети. Удаленные агенты устанавливаются по одному в каждый коллизионный домен тестируемой конфигурации и настраиваются только на генерацию конкретного типа трафика в заданном направлении (по конкретным МАС-адресам).
Если станции домена А должны работать c сервером MAIN по протоколу TCP/IP, то агент домена А надо настроить на генерацию TCP-трафика (далее тестовый трафик) в домен сервера MAIN. При этом генерация трафика должна осуществляться не по MAC-адресу сервера MAIN, а на MAC-адрес специально установленной для данных целей станции. Такую станцию будем называть "Приемником". Задача станции "Приемник" состоит в снятии нагрузки с сервера, так как в данном эксперименте мы проверяем устойчивость работы коммутатора, а не сервера.
Для организации встречного трафика из домена MAIN в домен А удаленный агент анализатора из домена MAIN должен быть настроен на генерацию TCP-трафика по МАС-адресу станции "Приемник" из домена А. При этом генератор трафика лучше не устанавливать на сервер MAIN, дабы не создавать ему дополнительную нагрузку. Аналогично все остальные агенты настраиваются на генерацию тестового трафика интересующих вас протоколов. Чтобы создать наихудшие для коммутатора условия, размер кадров можно установить равным минимально допустимому. Чем больше портов коммутатора и, соответственно, удаленных агентов анализатора протоколов будет участвовать в эксперименте, тем большую нагрузку вы создадите и, соответственно, более точные результаты получите.
Настроив и запустив генерацию тестового трафика со всех удаленных агентов, на ее фоне следует запустить одно или несколько приложений, которые вы планируете использовать в сети. Тем самым вы дополнительно проверите устойчивость работы приложений к высоким нагрузкам в сети. Например, какое-нибудь приложение, работающее с сервером MAIN, можно запустить на станции BOSS, находящейся в домене А. При этом центральный анализатор протоколов должен поочередно настраиваться на сбор и запись в файл трафика со всех портов коммутатора, где работают приложения: сначала из домена А, затем из домена MAIN, и так далее по всем доменам тестируемой конфигурации.
Теоретически центральный анализатор протоколов можно установить в одном из доменов сети, а каждый удаленный агент — заставить одновременно с генерацией трафика производить запись трафика. Но этого делать не рекомендуется, так как в этом случае нет гарантии того, что агент, производящий генерацию трафика, не окажется перегружен и не будет терять кадры.
После сбора и запаси в файлы пакетов со всех портов коммутатора они обрабатываются, например, с помощью программы NetSense for Observer. Цель обработки — определение числа повторно переданных пакетов на транспортном уровне во время работы конкретного приложения. Колонка Е (см. Рисунок 3) показывает число зафиксированных повторных передач пакетов при работе станции BOSS с сервером MAIN. Именно число повторно переданных пакетов является тем интегральным критерием, который свидетельствует о потере кадров.
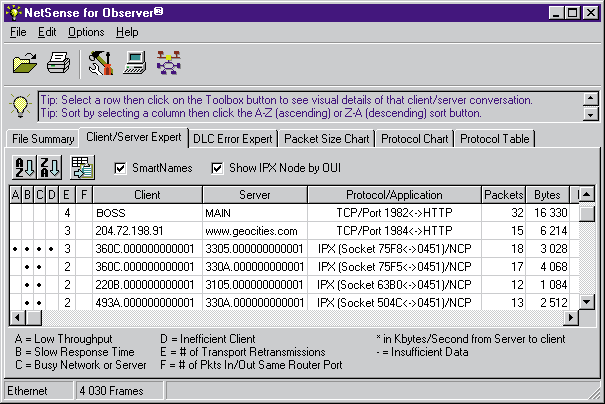
Рисунок 3. Режим Client/Server Expert программы NetSense for Observer (колонка Е) показывает число переповторов транспортного уровня, которые произошли при работе станции BOSS с сервером MAIN. Именно число переповторов является интегральным критерием, который свидетельствует о потере кадров.
Обнаружив потерю кадров, вы должны определить причину. В общем случае причин может быть несколько: перегрузка коммутатора, искажение данных при их передаче по каналу связи, слишком большое число эмулируемых коммутатором коллизий (эффект back pressure), несоблюдение коммутатором стандарта CSMA/CD. Эффект back pressure заключается в эмулировании коммутатором коллизий при перегрузке входного буфера. Вследствие этого после 16 последовательных коллизий драйвер сетевой платы на компьютере, где работает приложение, прекратит передачу кадра. Несоблюдение коммутатором стандарта CSMA/CD заключается в том, что коммутатор не выдерживает паузы в 9,6 микросекунд перед посылкой очередного кадра. В результате коммутатор будет непрерывно передавать данные, и никакая другая станция в этот момент в канал связи выйти уже не сможет. Такой эффект называется "блокировкой канала".
Поэтому при обнаружении повторных передач на транспортном уровне тот же самый трафик должен быть проанализирован с целью определения числа ошибок и повторных передач на канальном уровне. Это также может быть сделано с помощью программы NetSense for Observer (см. Рисунок 4). В результате анализа трафика вы сможете установить причину потери кадров от приложения на станции BOSS.
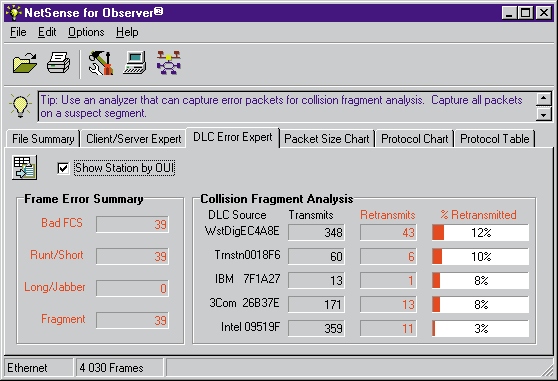
Рисунок 4. Режим DLC Error Expert программы NetSense for Observer позволяет определить число ошибок канального уровня и число переповторов канального уровня, которые произошли при работе станции BOSS (МАС-адресс WstDigEC4A8E). Переповторы канального уровня могут быть следствием как ошибок, так и коллизий.
Повторяя эксперимент и задавая различные параметры и интенсивность тестового трафика, вы можете построить зависимость между параметрами тестового трафика и числом повторно переданных пакетов на транспортном уровне. В результате вы сможете определить, при каких параметрах трафика и утилизации портов коммутатора пакеты начинают повторно передаваться на транспортном уровне и чем это вызвано.
Замечание №4. Значения параметров тестового трафика, при которых повторная передача пакетов на транспортном уровне дает о себе знать, могут служить в качестве ориентира при наблюдении за работой сети в процессе ее эксплуатации (для упреждающей диагностики). Эти значения с запасом в 10% должны быть введены как пороговые в диагностическое средство. Если в процессе эксплуатации сети значения параметров трафика превысят пороговые значения, то диагностическое средство информирует об этом событии администратора сети.
Нам часто задают вопрос, почему при низкой утилизации портов коммутатора (чаще всего Fast Ethernet или FDDI) и при отсутствии канальных ошибок сеть тем не менее периодически сбоит. Ответ прост. Наблюдение утилизации портов с помощью telnet или программ на базе SNMP дает усредненное, а не пиковое значение утилизации — так уж устроены SNMP-агенты. Однако именно при пиковых значениях утилизации коммутатор или станции могут терять кадры, вследствие чего пакеты передаются повторно на транспортном уровне.
Замечание №5. Вторым этапом стрессового тестирования сети является оценка устойчивости сервера и рабочих станций к высоким нагрузкам в сети.
Цель эксперимента — определение условий, при которых потеря кадров происходит именно на рабочих станциях и на сервере вследствие их перегрузки или скрытых дефектов.
Второй этап следует проводить после установки и подключения рабочих станций пользователей. Стрессовая нагрузка, которой сеть подвергается на втором этапе, должна быть на 10–15% меньше нагрузки, при которой пакеты на первом этапе начали повторно передаваться на транспортном уровне. Это даст вам гарантию того, что повторная передача вызывается отнюдь не потерей кадров в коммутаторе. Для этого на станциях пользователей в разных доменах сети необходимо одновременно с работой приложений запустить стрессовый тест типа Perform3 или FTest. В зависимости от размеров сети тест следует запускать в одном или нескольких доменах одновременно.
Суть работы программы FTest заключается в том, что станции будут взаимодействовать с сервером с постепенно увеличивающейся по интенсивности нагрузкой. В случае программы Perform3 нагрузка сразу будет максимальной, поэтому использование FTest более предпочтительно. При отсутствии указанных тестов вы можете просто запустить циклическую перекачку длинных файлов на сервер и обратно.
На этом этапе агенты анализатора протоколов надо настроить не на генерацию трафика, а на сбор пакетов. Это позволит вам измерить число канальных ошибок и коллизий и число повторно переданных пакетов на транспортном уровне в каждом домене сети. Анализ трафика позволит локализовать скрытые дефекты в рабочих станциях и на сервере и определить, в какой степени сервер и коммутатор сбалансированы друг с другом по производительности и какой запас пропускной способности имеется у каждого из них.
Полученные на первом этапе пороговые значения параметров трафика должны быть скорректированы с учетом результатов, полученных на втором этапе.
Диагностика сети.
Все многообразие средств, предназначенных для диагностики сетей, можно условно разделить на две категории в зависимости от принципа их работы: средства мониторинга и управления работой сети (далее средства мониторинга — monitoring software) и анализаторы сетевых протоколов (далее анализаторы протоколов — analyzers).
Принцип работы средств мониторинга основан на взаимодействии консоли оператора с так называемыми агентами, которые, собственно, и занимаются мониторингом и управлением работой устройств сети.
Примерами средств мониторинга являются программы Transcend компании 3Com, Optivity компании Bay Networks (ныне Nortel), HP OpenView Net Metrix. Подобные средства имеют множество достоинств, о чем написано достаточно много и совершенно справедливо. В данной статье мы будем рассматривать средства мониторинга только с точки зрения их применения для диагностики сети.
Агенты могут быть встроены в оборудование или загружены программным образом. Поскольку наиболее распространенным протоколом общения консоли оператора и агентов является SNMP, такие агенты часто называют SNMP-агентами.
SNMP-агенты могут выполнять самые различные функции в зависимости от типа баз управляющей информации (Managеment Information Base, MIB), которые они поддерживают. Эти функции могут включать в себя управление конфигурацией устройства, в которое агенты встроены (configuration management), управление контролем доступа к информации (security managеment), анализ производительности устройства (perfomance managеment), измерение числа ошибок при передаче данных (fault management) и другие.
Замечание №6. С точки зрения проведения диагностики сети с помощью средств мониторинга особое значение имеют следующие факторы: поддержка SNMP-агентами всех групп RMON MIB и наличие развитых функций по декодированию группы сбора пакетов RMON MIB.
При покупке активного оборудования особое внимание прежде всего следует обращать на то, какие базы управляющей информации поддерживают встроенные SNMP-агенты. Наибольшие возможности с точки зрения диагностики имеют SNMP-агенты, поддерживающие RMON MIB (RFC 1757). В этом случае в процессе эксплуатации сети вы сможете получать достоверную статистику по всем типам ошибок канального уровня. Если агенты не поддерживают RMON MIB, то информация об ошибках канального уровня обычно доступна только через Enterprise MIB. Enterprise MIB — это нестандартная база производителя оборудования. По этой причине интерпретация каких-то типов ошибок может быть не всегда корректна. Например, короткие кадры одни производители могут интерпретировать как коллизии, а другие — как короткие кадры.
Вся база управляющей информации RMON MIB разбита на 9 разделов или групп. Каждая группа отвечает за сбор определенной информации. Например, Statistics Group отвечает за сбор информации об ошибках канального уровня, Host Group — за сбор информации о трафике и т. д.
Особое значение в эффективной организации диагностики сети имеет последняя группа Packet Capture. Поддержка устройством этой группы дает возможность производить сбор трафика в сети для дальнейшего анализа и таким образом выявлять сбои в протоколах сетевого, транспортного и прикладного уровней, что особенно важно для диагностики. К сожалению, в настоящее время встроенные в оборудование SNMP-агенты не всегда поддерживают все 9 групп, и реже всего именно эту группу. Обычно сбор пакетов осуществляется только специальными аппаратными SNMP-агентами.
Развитые функции средств мониторинга по декодированию собранных пакетов повышают их эффективность при проведении упреждающей диагностики сети. К сожалению, очень немногие (в основном, только дорогие) средства мониторинга отображают информацию о собранных пакетах в удобной для анализа форме. Так, например, одна из наиболее распространенных программ сетевого мониторинга — программа Transcend for Windows компании 3Com — представляет информацию о содержимом собранных пакетов только в шестнадцатеричном виде, что очень неудобно.
Замечание №7. Если оборудование вашей сети поддерживает все группы RMON MIB, средства мониторинга имеют развитые функции по декодированию собранных пакетов, и вы знаете, как значения наблюдаемых параметров влияют на работу вашей сети, то средства мониторинга позволяют осуществлять очень эффективную упреждающую диагностику сети.
Если же хотя бы одно из перечисленных условий не выполняется, то эффективность использования средств мониторинга заметно снижается. Поскольку предварительное тестирование сети перед вводом в эксплуатацию проводится отечественными системными интеграторами очень редко и не все оборудование имеет встроенные SNMP-агенты с поддержкой всех групп RMON MIB, то в большинстве случаев дорогостоящие средства мониторинга используются неэффективно или вообще не используются.
Однако, даже при соблюдении всех вышеперечисленных условий, средства мониторинга недостаточны для проведения реактивной диагностики сети.
Реактивная диагностика.
При реактивной диагностике сети с помощью средств мониторинга измерительным прибором является SNMP-агент самого диагностируемого устройства. Однако при появлении сбоев показания SNMP-агента нельзя считать достоверными. Это особенно актуально, когда сбои происходят в самом устройстве с установленным SNMP-агентом. В таких случаях наблюдатель должен быть "независим" от диагностируемого устройства.
SNMP-агент устройства наблюдает за коллизионным доменом сети всегда только из одной точки и, что особенно важно для реактивной диагностики, не имеет возможности производить генерацию тестового трафика. В результате если не все оборудование имеет встроенные агенты, то часть ошибок канального уровня в домене сети может не фиксироваться.
Емкость буфера для сбора пакетов у SNMP-агентов с поддержкой группы Packet Capture ограничена. Например, для концентраторов SuperStack II компании 3Com — 500 Кбайт. Этого часто недостаточно для локализации сложных дефектов в сети.
Замечание №8. С точки зрения реактивной диагностики, т. е. возможности быстрой локализации дефектов в сети, применение анализаторов сетевых протоколов оказывается предпочтительным. Они представляют собой значительно более мощное средство по сравнению со средствами мониторинга сети, так как лишены всех перечисленных выше недостатков. Именно возможность эффективного проведения реактивной диагностики является сегодня актуальной задачей для администраторов сетей. Кроме того, работа с анализатором сетевых протоколов весьма поучительна.
Принцип работы анализатора протоколов отличается от принципа работы средства мониторинга сети. Анализатор сетевых протоколов исследует весь проходящий мимо него сетевой трафик. Локальные сети по своей природе являются широковещательными, т. е. каждый кадр от любой станции в пределах коллизионного домена видят все станции этого домена сети. Подключая анализатор к любой точке коллизионного домена сети, вы будете видеть весь трафик в этом домене.
Анализаторы протоколов предоставляют возможность собирать данные о работе протоколов всех уровней сети и, в большинстве случаев, способны производить генерацию тестового трафика в сеть. Имея большой буфер для сбора пакетов, анализаторы протоколов позволяют быстро локализовать причину сбоя в сети: например, обнаружить факт перегрузки конкретного сервера, бесследное исчезновение пакетов транспортного уровня на неисправных сетевых платах, коммутаторах и маршрутизаторах, IP-пакеты с неправильной контрольной суммой, дубликаты IP-адресов и многое другое.
Анализаторы протоколов можно разделить на две категории: программные и аппаратные (или программно-аппаратные). Программный анализатор — это программа, которая устанавливается на компьютер с обычной сетевой платой. Анализатор протоколов переводит сетевую плату компьютера в режим приема всех пакетов (promiscous mode). Примерами программных анализаторов протоколов являются Observer и Distributed Observer компании Network Instruments, NetXray компании Network Associates, LANalyzer for Windows компании Novell и многие другие.
Замечание №9. При проведении диагностики сети с помощью программного анализатора протоколов особое значение имеют типы сетевой платы и драйвера, на которых программному анализатору протоколов приходится работать. Типы сетевой карты и типы драйвера определяют возможность программного анализатора протоколов фиксировать ошибки в сети на канальном уровне.
Если программный анализатор протоколов установлен на компьютере, сетевая плата или сетевой драйвер которого не умеют фиксировать ошибки на канальном уровне, вы не сможете получить достоверную картину наличия ошибок в вашей сети. В этом случае анализатор протоколов нельзя эффективно использовать, так как он может показывать, что ошибок в сети очень мало, в то время как на самом деле их может быть очень много.
Ситуация еще усугубляется следующим фактом. Анализатор протоколов может сообщать, что драйвер умеет фиксировать ошибки канального уровня, тогда как в действительности же он их не фиксирует. Информация о том, какой тип ошибок может фиксировать конкретный тип драйвера при использовании конкретного типа сетевой платы, не является, к сожалению, общедоступной. Таким способом производители программных анализаторов протоколов пытаются защитить себя от хакеров и любителей нелицензионного ПО.
Господам хакерам и любителям использовать демонстрационные версии продуктов для диагностики своих сетей следует об этом помнить. Если найти нелицензионную копию какого-то программного анализатора протоколов или "вскрыть" защиту при большом желании не составляет особого труда, то узнать, какой тип драйвера с каким типом сетевой платы предоставляет достоверную информацию об ошибках в сети, — задача отнюдь не тривиальная. Не имея проверенной информации подобного рода, проводить диагностику сети вообще не имеет смысла, так как полученные результаты не будут отражать реальное состояние сети.
Аппаратный анализатор протоколов — это специализированный прибор или специализированная сетевая плата. И в том и в другом случае аппаратный анализатор имеет специальные аппаратные средства, с помощью которых он может проводить более детальную диагностику сети, чем при использовании программного анализатора. Аппаратные анализаторы выпускаются компаниями Network Associates, NetTest, Hewlett-Packard, RadCom, Wandel&Goltermann и другими.
Аппаратные анализаторы протоколов имеют возможность очень точно выявлять все дефекты канального уровня. Кроме этого, многие аппаратные анализаторы производят экспертный анализ трафика "на лету", т. е. в момент сбора пакетов. При использовании программного анализатора протоколов пакеты необходимо сначала собрать, и только потом полученную информацию можно анализировать с помощью специальной программы.
Замечание №10. Если задача состоит только в диагностике локальной сети, то предпочтение следует отдать программному анализатору протоколов. Если вы планируете проводить диагностику как локальных, так и телекоммуникационных сетей (ATM, SDH, frame relay и т. п.), то лучше выбрать аппаратный анализатор протоколов.
С точки зрения диагностики локальной сети преимущества аппаратных анализаторов по сравнению с программными анализаторами несоизмеримы с разницей в цене между ними. Аппаратные анализаторы стоят, как правило, более чем в 15—20 раз дороже, чем программные. Именно по этой причине в настоящее время новые модели аппаратных анализаторов, предназначенные для диагностики только локальных сетей, уже не разрабатываются.
Большинство выпускаемых в настоящее время аппаратных анализаторов представляет собой базовую модель (шасси) и набор модулей, каждый из которых предназначен для диагностики конкретного типа сети, как локальной, так и телекоммуникационной.
Анализаторы протоколов могут быть локальными, т. е. предназначенными для диагностики только одного домена сети, или распределенными. Последние позволяют одновременно проводить анализ большого числа (как минимум двух) доменов сети.
Примером программного локального анализатора может служить LANalyzer for Windows компании Novell. Примером программного распределенного анализатора протоколов — Distributed Observer компании Network Instruments. Большинство аппаратных анализаторов протоколов являются, как правило, локальными. Исключение составляет Distributed Sniffer.
Распределенный анализатор протоколов представляет собой центральный анализатор и набор удаленных агентов, каждый из которых взаимодействует с центральным анализатором по специальному протоколу. В отличие от SNMP-агента, агенты распределенного анализатора являются полноценными анализаторами протоколов. Единственное их отличие от центрального анализатора заключается в том, что они не выводят собираемую ими информацию на экран компьютера, на котором работают. Вся собираемая информация передается по сети на центральный анализатор.
Передача информации от агентов на центральный анализатор производится не постоянно, а только по запросу от центрального анализатора. По этой причине трафик между центральным процессором и удаленными агентами оказывается очень незначительным.
Чаще всего агенты программного распределенного анализатора протоколов являются сервисами NT или процессами под Windows 95. Таким образом, они могут работать на компьютерах обычных пользователей, не мешая им и одновременно диагностируя домен сети, куда они подключены.
Замечание №11. Для реактивной диагностики сети распределенные анализаторы протоколов имеют ряд существенных преимуществ перед локальными. Кроме этого, распределенные анализаторы протоколов в большинстве случаев не уступают средствам мониторинга сетей при проведении упреждающей диагностики, особенно в тех случаях, когда не все оборудование оснащено встроенными SNMP-агентами с поддержкой всех групп RMON MIB.
Первое преимущество распределенного анализатора перед локальным очевидно: чтобы провести диагностику каждого домена сети, анализатор протоколов не нужно переносить или переключать из домена в домен. Однако он имеет и другие преимущества.
Замечание №12. Для локализации ряда дефектов сети необходимо одновременно наблюдать за двумя и более сегментами (коллизионными доменами) сети. Это можно сделать только с помощью распределенного анализатора протоколов.
Данное замечание лучше всего пояснить на примере. Предположим, что в локальной сети, изображенной на Рисунке 5, станция BUCH, расположенная в домене А, периодически "зависает" (работает неустойчиво). При этом зависание происходит в непредсказуемые моменты времени.
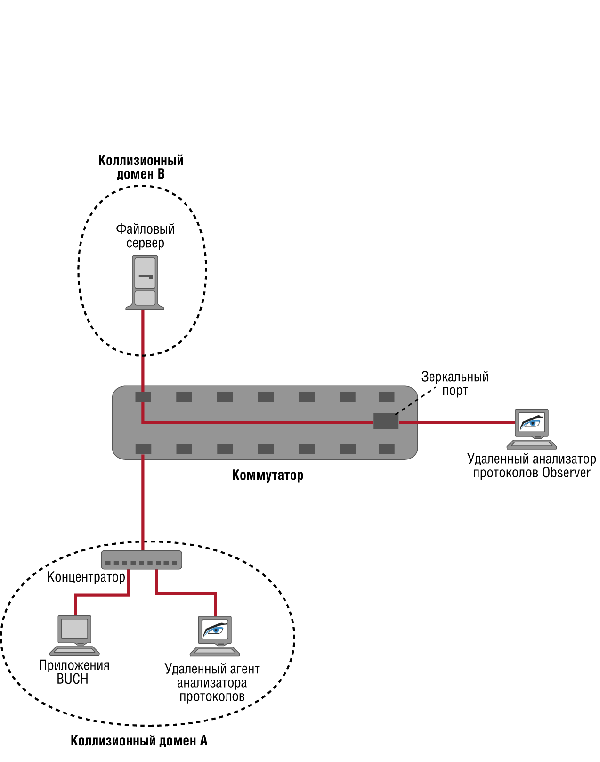
Рисунок 5. Часто достоверно определить причину неустойчивой работы станции BUCH, можно только путем анализа канальных трасс, снятых в одно и то же время в домене А и домене В.
Заключение.
Средства мониторинга сетей позволяют решать все основные задачи упреждающей диагностики, если все оборудование оснащено агентами с поддержкой группы сбора пакетов RMON MIB. Они в существенно меньшей степени пригодны для решения задач реактивной диагностики, так как у них отсутствует возможность генерации трафика.
Программные локальные анализаторы протоколов вполне подходят для задач реактивной диагностики (но в несколько меньшей степени, чем аппаратные анализаторы и распределенные программные анализаторы). С точки зрения упреждающей диагностики они могут эффективно использоваться только в малых сетях, состоящих из одного домена.
Аппаратные анализаторы протоколов в несколько большей степени, чем программные, способны решать задачи как реактивной, так и упреждающей диагностики. С нашей точки зрения, при правильном использовании программных анализаторов достоинства аппаратных средств оказываются не столь значительными и несоизмеримы с разницей в цене между ними.
При выборе в качестве критерия интегрального показателя (стоимость+возможности решения задач реактивной и упреждающей диагностики), наилучшими характеристиками, с нашей точки зрения, обладают распределенные анализаторы протоколов. Они иногда уступают средствам сетевого мониторинга в решении вопросов упреждающей диагностики — прежде всего, в тех случаях, когда сеть построена на базе коммутатора, у которого нет зеркального порта и отсутствуют агенты для конкретного типа ОС. Однако тенденция их развития такова, что в ближайшем будущем этот недостаток будет устранен. Так, например, компания Network Instruments объявила о выходе новой версии анализатора Distributed Observer с поддержкой SNMP-агентов с RMON MIB.
С точки зрения решения задач реактивной диагностики возможности программных распределенных анализаторов очень высоки. Они уступают локальным аппаратным анализаторам в выявлении проблем канального уровня, но превосходят их в решении проблем более высоких уровней, особенно в распределенных сетях. Таким образом, мы условно приравняли их возможности друг к другу.
Нельзя не сказать, что наибольшими возможностями, со всех точек зрения, обладают распределенные аппаратные анализаторы (например, Distributed Sniffer). Однако, принимая во внимание "заоблачную" цену этого продукта, мы не рассматриваем это средство в нашей статье.
На протяжении ряда лет большинство вопросов повышения производительности и надежности сетей решалось закупкой новой техники. Не всегда подобное решение было технически и экономически обоснованно, но почти всегда оно позволяло достигнуть желаемой цели — сеть начинала работать быстрее и лучше. При наличии 200% запаса пропускной способности практически все "узкие места" можно без труда "расширить", а приобретая только самое дорогое оборудование лидеров сетевых технологий, вы можете с большой степенью вероятности обезопасить себя от "скрытых дефектов".
Список литературы.
1.”Основы диагностики сети”, Сергей Юдицкий, Владислав Борисенко, Олег Овчинников
2. Таненбаум Э. Компьютерные сети. / 4-е изд. – СПб.: Питер, 2003. – 992 с.
3. Wikipedia.org |
| Категория: Домашние задания (по сетям МИФИ) | Добавил: igor18 (29.12.2012)
| Автор: Серяпов В.
|
| Просмотров: 1998
| Рейтинг: 0.0/0 |
Добавлять комментарии могут только зарегистрированные пользователи. [ Регистрация | Вход ] |
|